
Abstract
The goal of blind image super-resolution (BISR) is to recover the corresponding high-resolution image from a given low-resolution image with unknown degradation. Prior related research has primarily focused effectively on utilizing the kernel as prior knowledge to recover the high-frequency components of image. However, they overlooked the function of structural prior information within the same image, which resulted in unsatisfactory recovery performance for textures with strong self-similarity. To address this issue, we propose a two stage blind super-resolution network that is based on kernel estimation strategy and is capable of integrating structural texture as prior knowledge. In the first stage, we utilize a dynamic kernel estimator to achieve degradation presentation embedding. Then, we propose a triple path attention groups consists of triple path attention blocks and a global feature fusion block to extract structural prior information to assist the recovery of details within images. The quantitative and qualitative results on standard benchmarks with various degradation settings, including Gaussian8 and DIV2KRK, validate that our proposed method outperforms the state-of-the-art methods in terms of fidelity and recovery of clear details. The relevant code is made available on this link as open source.
Similar content being viewed by others


Introduction
The task of image super-resolution (SR) is to reconstruct clear high-resolution images from low-resolution images. Image degradation is often considered as the inverse problem of SR, as it involves mathematically modeling the processes that deteriorate the quality of image. According to previous works1,2,3,4,5, the pipeline of degradation is typically modeled as Eq. (1).
where x represents the high resolution (HR) image, while y corresponds to the low resolution (LR) image. The operator \(*\) denotes the two-dimensional convolution operation and \(k_{h}\) is the Gaussian kernel, \(\downarrow _{s}\) means downsampling operation with a scale factor of s, n refers to additive Gaussian white noise (AGWN). The classical SR methods6,7,8 assumes that the degradation pipeline is a single bicubic downsampling. However, if the predefined degradation does not exactly match the practical situation, the reconstructed HR image may exhibit unpleasant artifacts1. Therefore, recovering shape edges and rich details in the case of LR images with unknown degradation1,2,5,9,10,11,12, is an extremely meaningful and challenging task.
The most common blind SR schemes are typically divided into two stages: the first stage is to model the kernel explicitly or implicitly through optimizing a deep neural network from the degraded image1,2,3,4,5,9, and the second stage inputs the LR image combined with additional degradation prior through the SR network to obtain reconstructed HR image. In first stage, the mismatch between estimated blur kernel and the actual one can lead to over-smoothed or over-sharpened results1,2,3. An available solution is to perform accurate estimation of the kernel1,9 and robust integration with the SR backbone2,3,5.
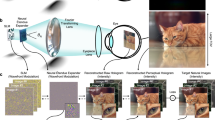
Recent research1,2,3,4,5,9 has mainly concentrated on the first stage of kernel modeling. DCLS3 proposes a robust dynamic kernel estimation network and introduces a module to achieve degradation representation embedding. However, its SR network has limited ability to represent spatial features, making it difficult to recover structural information well. Fig. 1 shows the reconstruction results of state-of-the-art methods and our method for structural textures. It can be observed obviously that current methods lacks the combination of structural prior knowledge, making the ambiguous details and edges in the recovered SR image.

It is broadly recognized that non-local operations15,16, which introduce self-similarity priors, are significant for recovering recurring textures within the same image. Moreover , the spatial attention and channel attention mechanisms can effectively capture local features. Motivated by these observations, we propose a network combined kernel estimation and structural prior knowledge that can leverage both local spatial and global features to boost reconstruction performance for images with high self-similarity. To be specific, we employ the deep constrained least squares3 (DCLS) block as the module to deblur the original feature \(f_o\), in order to obtain a clean feature \(f_c\). Next, we divide the original feature \(f_o\) into two vectors along the channel dimension: \(\widehat{f_o}\), and \(\overline{f_o}\). These three vectors \(f_c\), \(\overline{f_o}\), and \(\widehat{f_o}\), are together fed into a series of triple path attention blocks (TPAB) to perform deep feature extraction and utilize local spatial information to compensate for the gap caused by kernel estimation. Furthermore, the global texture fusion block (GTFB) adaptively adjusts the self-similarity scores of non-local features to achieve the embedding of global structural prior. We have performed several standard experiments on benchmarks with various degradation settings to evaluate our proposed method. The quantitative and qualitative results demonstrate that our network has excellent performance in all datasets, particularly for images with rich structural information. The main contributions of this paper are summarized as follows:
-
We propose a blind SR network, capable of combining kernel estimation with structural prior knowledge to reconstruct the textures with high self-similarity.
-
We employ a channel split strategy to take advantage of the original local spatial and channel features in order to compensate for artifacts generated by the kernel estimation and the deblurring operation.
-
We design a global texture fusion block that aggregates local spatial features with non-local operations to enhance recovery performance in images with high self-similarity.
-
Extensive experiments with various degradation settings demonstrate that our method achieves outstanding performance in the task of blind SR.
Related work
SR of bicubic and multiple degradation
The pioneering work of SRCNN6 has successfully motivated interest among researchers in the field of SR. Inspired by hierarchical architecture7,8,17 and robust loss function11,12,18,19,20,21, CNN-based methods have achieved outstanding performance on predefined bicubic downsampling in the SR task, while the degradation process in the real-world are generally unknown and complicated11,12. In practical applications, if the bicubic kernel assumed by classical methods does not match the actual degradation kernel, it will lead to unpleasant artifacts in the reconstructed SR image, severely affecting the visual perception quality. This discrepancy between the assumed kernel and the actual kernel give rise to domain gap22,23,24, which is a challenge in practical applications of SR.
Another approach to non-blind SR method4,25,26,27,28 is designed to super-resolve multiple types of degraded images with corresponding kernels. These methods make classical SR networks more robust and applicable to a wider range of real-world scenarios. FFDNet25 utilizes a noise level map as additional input, allowing it to handle various noisy images affected by different types of degradation. Similarly, SRMD4 proposes a kernel stretching strategy that incorporates the two degradation parameters, the blur kernel k and the noise level n, together with the LR as input to SR network. Zhang et al.29 combines learning-based methods with model-based methods to design an end-to end unfolding networks that can handle various types of degraded images with different scales. UDVD27 introduces dynamic convolution in the kernel estimation network, where the parameters of the filters can be dynamically adjusted based on the adaptivity of the input degraded image. KMSR26 utilizes generative adversarial networks to learn the distribution of kernels in real degraded images. Inspired by KMSR26, Son et al.28 propose an adaptive downsampling model that employs an unsupervised approach to simulate the actual degradation process of real-world images. They then synthesize paired data and develop an SR network capable of handling various types of degradation.
SR of unknown kernel
The most common approach for the blind SR task is based on kernel estimation methods1,2,3,4,5,9,30. KernelGAN9 utilizes cross-scale image similarity to accomplish kernel estimation on specific images and combined it with a classical method13 to achieve blind reconstruction. MANet30 further investigates spatially variant blur kernels in order to super-resolve objection motion and out-of-focus in real world scenarios. Gu et al.1 use an iterative correction method to alleviate the effects caused by the mismatch between estimated result and practical kernel. Luo et al.2,5 adopt an end-to-end network to alternately optimize estimator and restorer. These two methods1,2 are effective but time-consuming owing to the elaborate optimization steps. DCLS3 reformulates a practical degradation model and proposes a deep constrained least squares module to operate deconvolution in order to achieve robust degradation awareness. In the aforementioned methods1,2,3,5,9,22,23, the solution is concentrated on modeling degradation either implicitly22,23,31 or explicitly1,2,3,4,5,9,10,32 without delving into the function of structural textures as prior knowledge. This may be a potential factor leading to the upper bound of blind SR performance.

The overall architecture of our network and the structure of related blocks. Given an LR image, we first estimate the kernel k, and feed into DCLS module to achieve degradation presentation embedding. The triple path attention groups utilize the clean feature \(f_c\) and the chunked original feature \(\overline{f_o}\) and \(\widehat{f_o}\) as input to restore the clean SR image.
Method
Architecture
In this subsection, we will introduce the overall architecture of our model. As shown in Fig. 2, our method mainly contains two stages: degradation representation embedding, and texture details recovery. The first stage includes the dynamic kernel estimation and deblurring operation based on the DCLS3 module. The estimator \(N_e\) accomplishes robust kernel estimation from degraded LR image. Next, the LR image and the estimated blur kernel k are jointly input into the DCLS module for deblurring. Lastly, the clean and original shallow features are fed into the triple path attention network to achieve local and global features fusion, which consists of triple path attention blocks (TPAB) and global texture fusion blocks (GTFB). Details on the pipeline of our method and the relevant blocks will be described in the following subsections.
Degradation representation embedding

The overall architecture of dynamic kernel estimation. Given an LR image input, it first generate four specific filters. Then, these filters convolved sequentially with an identity kernel \(I_k\) to produce a single kernel k with a larger receptive field corresponding kernel size.
Inspired by the work of3, our method employs the dynamic kernel estimation, as shown in Fig. 3. Given an LR image with unknown degradation as input, three residual blocks are applied to extract deep features \(f_s\), followed by global average pooling to obtain the flattened features \(\overline{f_s}\). The fully connected layer maps the specific degradation information to the four various filters, \(\widehat{h_0}\) , \(\widehat{h_1}\) , \(\widehat{h_2}\) , and \(\widehat{h_3}\) , with kernel sizes set to \(11\times 11\), \(7\times 7\), \(5\times 5\) and \(1\times 1\), respectively, to adjust the receptive filed consistency with the kernel sizes of predicted kernel k. The process of dynamic estimation is shown in Eq. (2).
where \(I_k\) is the identity kernel, and \(\widehat{h_0}\) , \(\widehat{h_1}\) , \(\widehat{h_2}\) , and \(\widehat{h_3}\) are specific filters mapped from degradation information, k is the estimated kernel through Estimator \(N_e\). The \(I_k\) is sequentially convolved with these filters, enabling the parameters in network \(N_e\) to vary with different degraded inputs. Meanwhile, the DCLS3 module utilizes deconvolutional operations to obtain clean feature as Eq. (3).
where \(f_{o}\) represents the blurry original features extracted by a \(3\times 3\) convolution layer and three residual blocks from the LR image, k is the kernel predicted by the network \(N_e\), \(f_{c}\) represents the deblurred clean features through the deconvolutional operation via the DCLS3 module.
Texture details recovery
Even with introducing deconvolutional operation through the DCLS3 module, the damaged high-frequency information cannot be fully restored. Therefore, we propose a novel network that not only strongly extracts local features to compensate for the decline of high-frequency components but also incorporates non-local15,16 operation to fuse the local and global features.
Figure 2 illustrates the proposed SR network, mainly consists of the extraction process of original features and the fusion process of local features with global features. A \(3\times 3\) convolutional kernel and three residual blocks without batch normalization33 is used to extract original features \(f_o\) as Eq. (4).
where \(I_{LR}\in {R^{H\times W\times C}}\) is an LR image as input, H and W represent the height and width of the patch that is cropped from a sub-image, and C is the RGB channels in the image.
In previous stages we have obtained clean features \(f_c\). FAIG34 demonstrates that one branch network without degradation prior can achieve comparable performance to the two-branch method with degradation information. Although it may be reasonable to directly use the clean feature \(f_c\) as input to the SR network for recovery, the offset of kernel estimation9,30 and insufficiency of deblurring function in the DCLS3 module would prevent the SR network from effectively restoring highly structured textures in the SR backbone. Therefore, we propose a Triple Path Attention Group (TPAG) to extract deep feature f as Eq. (6).
where the \(\psi (fc,\overline{f_o},\widehat{f_o})\) represents TPAG that adopts the clean feature \(f_c\), chunked original feature \(\overline{f_o}\) and \(\widehat{f_o}\) as additional inputs, \(h_{GTFB}(h^n_{TPAB})\) means that the group is composed of n Triple Path Attention Blocks (TPAB) and one Global Texture Fusion Block (GTFB). f is the deep clean feature, N is the number of TPAG in our SR network.
In addition, we further refine the deep feature f through a \(3\times 3\) convolutional layer with the original low-frequency feature \(f_{o}\) connected through long skip connections7,8,35,36, as Eq. (7).
Finally, pixel shuffle37 serves as the upsampling module and completes the mapping from feature maps to HR image \(I_{SR}\).
Triple path attention block
Deep SR networks contain specific filters that can handle various types and levels of degraded images34. These specific filters, which can be used to address corresponding degradation such as noise and blur, are located at different positions and branches within a single SR network. Channel attention8,36,38,39 and spatial attention40,41 mechanisms can enhance the local modeling ability. Therefore, we introduce these mechanisms as two branches in TPAB, allowing the network to strengthen its generalization and better handle different types of degradation.
The triple path attention blocks, consisting of residual channel attention and residual local spatial blocks, is shown in Fig. 2. The original shallow features \(f_{o}\) are split into two feature maps \(\overline{f_o}\) and \(\widehat{f_o}\) along the channel dimension. They are combined with the deblurred clean features \({f_c}\) and passed through TPABs to refine local texture features and compensate for the loss of high-frequency texture details. Specifically, \(\overline{f_o}\) and \(\widehat{f_o}\) are processed respectively by residual channel attention branches8 and residual local spatial branches41 to extract deep local features. Meanwhile, \(\overline{f_o}\) and \(\widehat{f_o}\) are concatenated with \(f_o\) and fused by a convolutional layer. Lastly, the aggregated local features pass through a GTFB to establish connections between local and non-local features.
Global texture fusion block
Non-local15,16,42 operations are capable of capturing long-range dependencies between different parts of an image, addressing the limitation of receptive filed by introducing self-attention mechanisms that enable each position to attend to all other positions in the input data. This operation is particularly instrumental in restoring structural textures that exhibit strong self-similarity. Previous researchers15,42 hypothesized that non-local textures with higher similarity scores would be more advantageous for restoring edge information. However, they overlooked an objective fact that when an image suffers from severe degradation, non-local textures with low similarity scores may actually be more useful for restoring edges16.
Fusing the local spatial texture features without careful consideration does not significantly improve the network’s ability to restore textures. Therefore, we cascade a global texture feature fusion block (GTFB) at the end of each TPAG. In the module, we adopt the global learnable attention block16 after the local feature fusion. The global learnable attention block adaptively adjusts the similarity scores of non-local textures, allowing the network to effectively utilize non-local textures that previously had low similarity scores but can provide rich details.
As shown in Fig. 4, we input the feature map \(X\in R^{H\times W \times C}\) as the input and convert X into three 1D vectors Q, L and \(V\in R^{C\times HW }\) to achieve global attention mechanism. Super-Bit Locality-Sensitive Hashing (SB-LSH) divides the feature map into buckets to reduce computation costs, as shown in the Eq. (8).
where \(M \in R^{b\times c}\) is a randomly initialized orthogonal matrix and b is the number of hash buckets, \(X_i\in R^C\) is the \(i-th\) component of \(Q_i\), \(\lambda _i\) is the index set corresponding to \(Q_i\). Next, we use learnable similarity score \(X_l\) (LSS) and fixed dot product similarity score \(X_f\) (DPSS) to measure self-similarity as Eq. (9).
where \(S_f(X_i)=X^T_i X_i\), \(S_l(X_i)\) is defined as Eq. (10).
where \(\sigma\) is the ReLU activation and \(W_1, W_2, b_1, b_2\) are learnable parameters.

The details about global learnable attention16 block.
Loss function
Our model includes the kernel estimation task and the reconstruction task. We jointly optimize our model using \(L_1\) Loss \(L_{kernel}\) and Charbonnier Loss \(L_{pixel}\), as shown in the Eq. (11).
where the \(L_{kernel}=||k-k_l||\) is the \(L_1\) loss between estimated kernel k and the ground truth blur kernel \(k_l\). The pixel loss is defined as \(L_{pixel}=\sqrt{(I_{SR}-I_{HR})^2+\epsilon }\), where \(I_{SR}\) and \(I_{HR}\) denote the super-resolved image and the ground-truth HR image, \(\epsilon\) is a constant and usually \(1\times 10^{-6}\).
Experiments
Datasets and implementation details
Datasets and metrics
Following previous work1,2,5, we used the DIV2K50 (800) and the Flickr2K51 (2650) as the training data, which together contain 3450 2K HR images. We adopt both isotropic and anisotropic Gaussian kernels as assumed degradation to synthesize corresponding LR images according to Eq. (1). The experimental results are evaluated using the PSNR and SSIM52 metrics for fidelity, which are only calculated on the Y channel of the YCbCr color space.

Isotropic Gaussian kernels
In the setting 1, isotropic Gaussian kernels are first applied in our study as the same in1,2,3,5. The kernel size is fixed to \(21\times 21\) during both the training and testing phases. During the training process, we randomly sampled the kernel width from the ranges of [0.2, 2.0] , [0.2, 3.0] , and [0.2, 4.0] uniformly for scale factors of 2, 3, and 4, respectively. During the testing phase, we used Gaussian8 kernels to degrade five benchmarks, including Set543, Set1444, B10045, Urban10046, and Manga10947. Gaussian8 uniformly selects 8 kernels from the ranges [0.80, 1.60], [1.35, 2.40], and [1.80, 3.20] for scale factors 2, 3, and 4, respectively. Subsequently, the HR images are convolved with 8 various blur kernels and downsampled to obtain corresponding LR images.
Anisotropic Gaussian kernels
In the setting 2, anisotropic Gaussian kernels were employed in our study follwing the work in1,2,3,5,9. The kernel size is \(11\times 11\) and \(31\times 31\) for scale factors 2 and 4 respectively in the training stages. During the training process, we randomly sampled the kernel width from the ranges of [0.6, 5] and rotated it from the range \([\) \(-\pi\) \(,\) \(\pi\) \(]\). During the testing process, blind SR benchmark DIV2KRK9 were used for evaluation.
Implementation details
We cropped the training data into sub-images of size \(480\times 480\), and utilized LR patches of size \(64\times 64\) to feed into our model. Our SR network consists of 6 groups of TPAG, each consisting of 11 TPABs and 1 GTFB. We trained the model using 8 RTX2070 GPUs, with a batch size of 4 for each GPU. The initial learning rate was \(1\times 10^{-4}\) and decayed by half at every \(2\times 10^{5}\) iterations, the total number of iterations was \(1\times 10^{6}\). We used the Charbonnier loss21 as loss function and Adam53 optimizer with \(\beta _1\) 0.9 and \(\beta _2\) 0.99 for optimization. We also adopt horizontal flipping and \(90^{\circ }\) rotation as data augmentation strategies during the training phase.
Comparison with state-of-the arts
Evaluation with isotropic Gaussian kernels
We have evaluated our method on benchmarks synthesized by Gaussian8 kernels and compared its performance with those using state-of-the-art blind SR methods, including ZSSR13, IKC1, DANv15, DANv22, AdaTarget14, KOALAnet32, and DCLS3. Additionally, CARN48 as a lightweight non-blind SR model that combined with blind deblurring49 method was also implemented for comparison.
The quantitative comparisons on benchmarks with Gaussian8 kernels are shown in Table 1. Our method achieves remarkable results on various benchmarks, particularly exhibiting noticeable performance on datasets with strong self-similarity, such as Urban10046 and Manga10947, nearly + 0.16dB and + 0.15dB than DCLS3 on \(\times\)4 factor. Bicubic interpolation and CARN48 are non-blind SR methods that assume a known bicubic degradation, which deviates from the actual situation, resulting in a severe drop in performance. ZSSR13 utilizes the internal statistics of patch recurrence to build an image-specific super-resolution method that does not require external datasets. This approach slightly improves performance due to the lack of abundant training data and powerful fitting ability. Performing the blind deblurring49 operation on the reconstructed image can moderately improve performance by reducing artifacts caused by domain gap. Conversely, applying the inverse operation may further damage details in the LR image, leading to unsatisfactory SR results. The IKC1 and DAN5 compensate for the offset caused by kernel estimation through iterative correction and end-to-end alternate optimization, respectively, significantly improving the performance. DCLS3 can retain the spatial information of the blur kernel while introducing dynamic convolution to boost the robustness of estimation, thus achieving superior performance.
Our proposed TPAB compensates for the attenuation of high-frequency components caused by the DCLS3 deconvolution module and the GTFB integrates non-local features with low similarity scores to assist in the fusion of local and global features. The qualitative visual results in Fig. 5 also demonstrate that our method is capable of recovering sharp edges and rich details. Furthermore, considering the complexity of actual degradation, we conduct an extra experiment to handle images with Gaussian8 kernels and additional noise. The quantitative results, shown in Table 2, validate that our method also has a certain degree of robustness to additional noise.
Table 3 shows the quantitative results of these methods on the DIV2KRK9 dataset. The results indicates that ZSSR13 can serve as a method for improving bicubic interpolation performance. When combined with the kernel estimation by KernelGAN9 as a prior, the performance of ZSSR13 is further improved. SRMD4 shows the consistently with bicubic interpolation. Classical SR methods such as RCAN8, EDSR7, and DBPN54, which adopted paired training data degraded by bicubic downsampling, suffer an extreme decrease in performance due to domain gap. The correction filter55 modifies the blurry image to match bicubic kernel, significantly improving the performance of DPBN54 trained on bicubic kernel.
Among the remaining blind SR methods, which contain IKC1, DAN2,5, KOALAnet32, AdaTarget14,and DCLS3, our method performed slightly superior than the DCLS3. This circumstance is consistent with our hypothesis. Due to the wild degradation of the DIV2KRK9 dataset, the textures and edges are damaged severely. The compensation of TPAB module for high-frequency features is limited. GTFB cannot accurately adjust the similarity score of local textures, resulting in the reconstruction of high-frequency information that is not as good as isotropic Gaussian kernels with mild degradation.
Ablation study and discussion
In this subsection, we performed a series of ablation experiments on the two crucial modules proposed by us, TPAB and GTFB, to quantitatively study their contributions to our method. The specific settings related to the ablation experiments are shown in the Table 4.
Firstly, the DCLS3 adopt clean feature \(f_c\) with original \(f_o\) as input to feed into Double Path Attention Groups (DPAG) to reconstruct HR images. The DCLS was used as baseline to explore the function of our proposed modules TPAB and GTFB.
Secondly, we placed DPAG with our proposed TPAG, where original feature \(f_o\) was split into \(\overline{f_o}\) and \(\widehat{f_o}\) to extract channel and spatial local feature to compensate for high-frequency decline. In this setting, without the function of global feature fusion, the single GTFB was placed by a TPAB. It can be observed from Table 5 that adding only the TPAB module resulted in a minimal improvement in performance(+ 0.02db in Set1444 and + 0.01dB in Manga10947). This may be because the depth of TPAG is already sufficient for extracting degradation feature, and using TPAB alone to capture local texture features has limited compensatory effects on high-frequency information.
Lastly, we utilized a variant network consisting of Double Path Attention blocks (DPAB) and Global texture fusion block to evaluate the contribution of GTFB, we appended a GTFB in each DPAG. The results shows a similar trend to the previous experiments, indicating GTFB could better utilize non-local textures to reconstruct high-frequency details. However, due to the lack of tiny compensation from the TPAB module, there is only a moderate performance improvement(about + 0.05dB in Urban10046), and the ability to reconstruct texture information was still insufficient.
Performance on real degradation
To further demonstrate the effectiveness of our method, we utilized the proposed model with isotropic Gaussian kernels and additional noise level 15 on real degradation images where the degradation is complicated and unknown. Our model was compared with classical real-world super resolution methods including RealSR10, BSRGAN11, Real-ESRGAN12, DASR31, and MM-RealSR56 on Real2011 dataset. An example of super-resolving chip image is shown in Fig. 6. Our method still produce rich details and sharp edges.
Discussion
The specific results of the ablation experiments are shown in Table 5. It is evident that adding either module alone only results in a marginal performance gain(approximately + 0.05dB in Set1444 and BSD10045). However, the flexible combination of two modules achieves astonishingly higher performance (+ 0.16dB and + 0.13dB in Urban10046 Manga10947 respectively than only one module). One possible reason is that even slight compensation of high-frequency information is crucial for the adaptive adjustment of similarity scores in global learnable attention16 block. With the aggregation of local features on both channel and spatial dimensions introduced by the TPAG module, the GTFB exhibits a stronger ability to fuse global information.
Limitation
Our model has achieved good results in super-resolving images with both synthetic degradation and real-world. However, since our training data only covers blurring and noise, without considering more severe and complicated degradation, our model’s performance is not satisfactory when facing images with wild degradation. Meanwhile, due to the dependence on predicting specific kernel parameters, the accuracy of kernel estimation still has a moderate impact on the reconstructed image. We also conducted a comparison of running time and mode size with state-of-the-arts methods, and the results are shown in Table 6. Due to the global information modeling performed by the GLA16 module, the computational cost is increased. And channel split strategy increases memory access cost, which is a significant factor affecting inference speed.

Conclusion
In this work, we propose a blind SR network that is capable of combining kernel estimation with structural prior knowledge. Our method consists of two steps: degradation representation embedding and texture details recovery. A triple path attention block was first proposed to extract local spatial and channel features to compensate for the loss of high-frequency components caused by the first steps.
Subsequently, the global texture fusion block was used to fuse local and global textures, thus providing complementary information for the recovery of HR images. A serious of experiments on benchmarks with different degradation settings demonstrates that our method achieves outstanding performance in blind SR. In future work, we primarily have three main tasks: First, we will utilize contrastive learning to predict the degradation representation of images to disguise different types and levels of degradation, rather than specific parameters of kernel. Second, we will attempt more practical degradation methods to further generalize the model to real-world images.
Code availability
The relevant code is made available on this link as open source.
References
Gu, J., Lu, H., Zuo, W. & Dong, C. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1604–1613 (2019).
Luo, Z., Huang, Y., Li, S., Wang, L. & Tan, T. End-to-end alternating optimization for blind super resolution. arXiv preprint arXiv:2105.06878 (2021).
Luo, Z. et al. Deep constrained least squares for blind image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17642–17652 (2022).
Zhang, K., Zuo, W. & Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3262–3271 (2018).
Huang, Y. et al. Unfolding the alternating optimization for blind super resolution. Adv. Neural Inf. Process. Syst. 33, 5632–5643 (2020).
Dong, C., Loy, C. C., He, K. & Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision. 184–199 (Springer, 2014).
Lim, B., Son, S., Kim, H., Nah, S. & Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 136–144 (2017).
Zhang, Y. et al. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision. 286–301 (2018).
Bell-Kligler, S., Shocher, A. & Irani, M. Blind super-resolution kernel estimation using an internal-GAN. Adv. Neural Inf. Process. Syst. 32, 284–293 (2019).
Ji, X. et al. Real-world super-resolution via kernel estimation and noise injection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 466–467 (2020).
Zhang, K., Liang, J., Van Gool, L. & Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4791–4800 (2021).
Wang, X., Xie, L., Dong, C. & Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1905–1914 (2021).
Shocher, A., Cohen, N. & Irani, M. “zero-shot” super-resolution using deep internal learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3118–3126 (2018).
Jo, Y., Oh, S. W., Vajda, P. & Kim, S. J. Tackling the ill-posedness of super-resolution through adaptive target generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16236–16245 (2021).
Wang, X., Girshick, R., Gupta, A. & He, K. Non-local neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7794–7803 (2018).
Su, J.-N., Gan, M., Chen, G.-Y., Yin, J.-L. & Chen, C. P. Global learnable attention for single image super-resolution. In IEEE Transactions on Pattern Analysis and Machine Intelligence. 1–12 (2022).
Tong, T., Li, G., Liu, X. & Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4799–4807 (2017).
Johnson, J., Alahi, A. & Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision. 694–711 (Springer, 2016).
Yuan, Y. et al. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 701–710 (2018).
Ledig, C. et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4681–4690 (2017).
Barron, J. T. A general and adaptive robust loss function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4331–4339 (2019).
Fritsche, M., Gu, S. & Timofte, R. Frequency separation for real-world super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 3599–3608 (IEEE, 2019).
Zhou, Y., Deng, W., Tong, T. & Gao, Q. Guided frequency separation network for real-world super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 428–429 (2020).
Luo, Z., Huang, Y., Li, S., Wang, L. & Tan, T. Learning the degradation distribution for blind image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6063–6072 (2022).
Zhang, K., Zuo, W. & Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 27, 4608–4622 (2018).
Zhou, R. & Susstrunk, S. Kernel modeling super-resolution on real low-resolution images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2433–2443 (2019).
Xu, Y.-S., Tseng, S.-Y. R., Tseng, Y., Kuo, H.-K. & Tsai, Y.-M. Unified dynamic convolutional network for super-resolution with variational degradations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12496–12505 (2020).
Son, S., Kim, J., Lai, W.-S., Yang, M.-H. & Lee, K. M. Toward real-world super-resolution via adaptive downsampling models. IEEE Trans. Pattern Anal. Mach. Intell. 44, 8657–8670 (2021).
Zhang, K., Gool, L. V. & Timofte, R. Deep unfolding network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3217–3226 (2020).
Liang, J., Sun, G., Zhang, K., Van Gool, L. & Timofte, R. Mutual affine network for spatially variant kernel estimation in blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4096–4105 (2021).
Wang, L. et al. Unsupervised degradation representation learning for blind super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10581–10590 (2021).
Kim, S. Y., Sim, H. & Kim, M. Koalanet: Blind super-resolution using kernel-oriented adaptive local adjustment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10611–10620 (2021).
Ioffe, S. & Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning. 448–456 (PMLR, 2015).
Xie, L., Wang, X., Dong, C., Qi, Z. & Shan, Y. Finding discriminative filters for specific degradations in blind super-resolution. Adv. Neural Inf. Process. Syst. 34, 51–61 (2021).
Yoo, J. et al. Rich CNN-transformer feature aggregation networks for super-resolution. arXiv preprint arXiv:2203.07682 (2022).
Chen, X., Wang, X., Zhou, J. & Dong, C. Activating more pixels in image super-resolution transformer. arXiv preprint arXiv:2205.04437 (2022).
Huang, C.-K. & Nien, H.-H. Multi chaotic systems based pixel shuffle for image encryption. Opt. Commun. 282, 2123–2127 (2009).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7132–7141 (2018).
Niu, B. et al. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision. 191–207 (Springer, 2020).
Liu, J., Zhang, W., Tang, Y., Tang, J. & Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2359–2368 (2020).
Kong, F. et al. Residual local feature network for efficient super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 766–776 (2022).
Mei, Y. et al. Pyramid attention networks for image restoration. arXiv preprint arXiv:2004.13824 (2020).
Bevilacqua, M., Roumy, A., Guillemot, C. & Alberi-Morel, M. L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In British Machine Vision Conference. 135.1–135.10 (BMVA Press, 2012).
Zeyde, R., Elad, M. & Protter, M. On single image scale-up using sparse-representations. In Curves and Surfaces. 711–730 (Springer, 2012).
Martin, D., Fowlkes, C., Tal, D. & Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision. Vol. 2. 416–423 (IEEE, 2001).
Huang, J.-B., Singh, A. & Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5197–5206 (2015).
Matsui, Y. et al. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 76, 21811–21838 (2017).
Ahn, N., Kang, B. & Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision. 252–268 (2018).
Pan, J., Sun, D., Pfister, H. & Yang, M.-H. Deblurring images via dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 40, 2315–2328 (2017).
Agustsson, E. & Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 126–135 (2017).
Timofte, R., Agustsson, E., Van Gool, L., Yang, M.-H. & Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 114–125 (2017).
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Haris, M., Shakhnarovich, G. & Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1664–1673 (2018).
Hussein, S. A., Tirer, T. & Giryes, R. Correction filter for single image super-resolution: Robustifying off-the-shelf deep super-resolvers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1428–1437 (2020).
Mou, C. et al. Metric learning based interactive modulation for real-world super-resolution. In Proceedings of the European Conference on Computer Vision. 723–740 (Springer, 2022).
Acknowledgements
This work was supported by National Natural Science Foundation of China under Grant 62171133, in part by the Artificial Intelligence and Economy Integration Platform of Fujian Province, and the Fujian Health Commission under Grant 2022ZD01003.
Author information
Authors and Affiliations
Contributions
J.Z. analyzed the results and wrote the manuscript,Y.Z designed the research framework. J.B., Q.Z. and Y.X. revised the manuscript, W.d. , W.H. ,T.Z. and K.S. provided support for the research. T.T. and Q.G. review and supervision. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, J., Zhou, Y., Bi, J. et al. A blind image super-resolution network guided by kernel estimation and structural prior knowledge. Sci Rep 14, 9525 (2024). https://doi.org/10.1038/s41598-024-60157-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-60157-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
