
Abstract
The behavioral and biological underpinnings of family planning (FP) unfold on an individual level, across a full reproductive life course, and within a complex system of social and structural constraints. Yet, much of the existing FP modeling landscape has focused solely on macro- or population-level dynamics of family planning. There is a need for an individual-based approach to provide a deeper understanding of how family planning is intertwined with individuals’ lives and health at the micro-level, which can contribute to more effective, person-centered design of both contraceptive technologies and programmatic interventions. This article introduces the Family Planning Simulator (FPsim), a data-driven, agent-based model of family planning, which explicitly models individual heterogeneity in biology and behavior over the life course. Agents in FPsim can experience a wide range of life-course events, such as increases in fecundability (and primary infertility), sexual debut, contraceptive choice, postpartum family planning, abortion, miscarriage, stillbirth, infant mortality, and maternal mortality. The core components of the model—fecundability and contraceptive choice, are represented individually and probabilistically, following age-specific patterns observed in demographic data and prospective cohort studies. Once calibrated to a setting leveraging multiple sources of data, FPsim can be used to build hypothetical scenarios and interrogate counterfactual research questions about the use, non-use, and/or efficacy of family planning programs and contraceptive methods. To our knowledge, FPsim is the first open-source, individual-level, woman-centered model of family planning.
Similar content being viewed by others


Introduction
Family planning (FP) behavior and biology unfold on an individual level, across a full reproductive life course, and within a complex system of social and structural constraints. Consequences of family planning, or lack thereof, likewise unfold individually—with greater contraceptive access and use repeatedly linked to better health for women and children1,2,3,4,5, and more empowered women6,7.
Yet, much of the existing FP modeling landscape has focused on macro- or population-level dynamics of family planning, with far less attention paid to individual needs and preferences8,9 or individual-level consequences10,11,12,13,14. Due to the individual nature of the biological and behavioral underpinnings of family planning and its consequences, deeper understanding of how family planning is intertwined with individuals’ lives and health at the micro-level can contribute to more effective, person-centered design of both contraceptive technologies and programmatic interventions.
To that end, this article introduces the Family Planning Simulator (FPsim), a data-driven agent-based model of family planning, which explicitly models individual heterogeneity in biology and behaviors over the life course to better understand the conditions under which we might expect contraceptive decision-making to change, and, in turn, to inform programmatic and policy decision-making to expand contraceptive choice and access. To our knowledge, FPsim is the first open-source, individual-level, woman-centered model of family planning. Despite the individual nature of family planning, few FP models center individual biology and behavior. As an agent-based model, FPsim allows researchers to better understand and interrogate the individual behavioral and biological dynamics that aggregate to macro-level fertility outcomes. Integrating individual-level dynamics into the model allows for explicitly modeling interventions and programming targeted to specific groups (i.e., adolescents, postpartum women) in a heterogeneous population.
In the following sections, we outline the need for an agent-based model in the family planning field, describe the model design, data and methods used to parameterize the model, and provide illustrative examples of using FPsim for research.
Agent-based modeling
Agent-based models (ABMs; also called individual-based models) simulate realistic or theoretical populations, allowing for adaptive behavior, in which agents interact with themselves, other agents, and their environments15. ABMs link individual-level dynamics to emergent population processes, and thus have been used in social sciences and population health to address a wide range of complex issues16,17,18. An incomplete list includes such a range of demographic topics as dynamic marriage markets16,19; the effects of family planning efforts on conserving panda habitat in China20; sex ratio at birth21; population change after armed conflict in Nepal22,23; migration and mobility24; and fertility decline and economic growth25.
Family planning modeling
Family planning biology and behavior unfold on the micro level. Fecundability, the biological capacity to conceive, is age-specific and subject to a great deal of individual variation26,27,28,29. Within households, women and couples make risk-benefit calculations at the micro-level, aligned with their preferences, desires, and intentions30,31,32. These intentions are dynamic as families grow33 and as women move through the life course: experiencing various states of health, reproductive outcomes, and social stability14,34.
Most agent-based models for family planning have been built to answer specific questions, e.g., helping couples with decision-making regarding delaying fertility if they have an ideal family size in mind35, the impact of assistive reproductive technology on fertility outcomes36, the influence of son preference on sex ratio at birth21, and the macro-level impact of family planning on environmental outcomes, such as panda habitat20.
Compartmental models have more commonly been used for policy and programmatic decision-making, such as Avenir Health’s Spectrum37 and Impact 238. These models have been developed as tools to understand a predefined set of impacts of family planning, but not necessarily to understand the dynamics driving family planning use in and of itself. A major statistical model used in FP, the Family Planning Estimation Tool or FPET39 projects future modern contraceptive prevalence and unmet need using historical patterns from health surveys and service statistics at the national level, but this model relies on S-curves—which have been critiqued40—and cannot explore deeper individual-level connections between contraception and reproductive health. To better understand subnational dynamics of common FP indicators, Mercer et al.41 built a Bayesian hierarchical model that leverages spatiotemporal smoothing to integrate multiple surveys and their designs. While each of these models presents a different tool for analyzing FP questions, none provide an individual-level model that integrates the complexities of family planning dynamics—biological and behavioral—over a woman’s full reproductive life course.
Introducing FPsim
Model description
FPsim is an agent-based, woman-centered, data-driven model that is designed to be flexible enough to address a wide range of questions and settings. It follows the full life courses of agents, who are exposed to family planning decisions, the risk of pregnancy, and a wide range of pregnancy outcomes. The model is modular and can be calibrated to whole populations (as we show in this manuscript) or subgroups.
Initialization and parameterization
FPsim users choose a calibrated location when running the model. FPsim is currently available for Senegal, and calibrated Kenya and Ethiopia options are in development—these pre-made calibrations can be used as examples, or users can calibrate the model to their setting of choice. The model is initialized with a historical population pyramid from the context. Men and women enter the model without children and non-pregnant. Initialization of agents without history of pregnancy or childbirth creates a fictional initial cohort that will tend to have skewed outcomes. Both men and women are initialized, but men are subject to aging and mortality alone, while women can go on to experience a wider range of events.
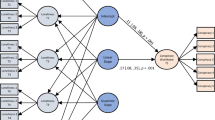
In FPsim, agents experience events and move from one state to another based on data-derived and assumption-based probabilities. Figure 1 maps the major states and events that FPsim agents can experience. For simplicity, we focus Fig. 1 on conception and pregnancy outcomes. A full list of all events in FPsim, and the data we use to parameterize them, are included in Table A1 of the Supplementary Materials. Agents are assessed for their eligibility (i.e., only pregnant women deliver; only women who are sexually active that month are eligible to conceive), and experience new events based on assigned probabilities.

The figure is a decision map displaying contraception and pregnancy-related events in FPsim. Reading from the top, each agent i in timestep j is checked for live status, and if alive, is checked for pregnancy status. If pregnant, the agent enters the pregnancy and childbirth module. If not, she continues on by checking if she is sexually active this month, the result of an age- and postpartum-specific set of probabilities. If she is sexually active, she is eligible for conception, and enters the conception module. Conception is a product of individual-level fecundability and contraceptive method efficacy (including 0% effectiveness of “None”). If she conceives, she may lose or terminate the pregnancy.
When the move to a new state or event is probabilistic, agents are assessed using a binomial trial—a random number between 0 and 1 is generated, and agents with an assigned probability higher than the random number will move or take that action. This allows for individual heterogeneity and, importantly for agent-based models, unpredictable behavior of some agents.
Thus, a single agent in FPsim experiences a simulated life course with probabilistic events related to her reproductive life and health. Figure 2 visualizes an example life course of a single FPsim-Senegal agent. How typical or atypical this agent is depends on the calibrated setting. For example, this agent may have average fertility for Senegal but higher than average for a lower fertility setting like Kenya.

LAM = lactational amenorrhea. The figure shows a reproductive life course for a single agent drawn from FPsim-Senegal. This agent has an underlying biological fecundability that changes as she ages, represented by the blue line. Over her reproductive life course, she is exposed to pregnancy to various degrees, based on her sexual activity (in blue) and her contraceptive coverage (dashed black bar). She also experiences several pregnancy events, including an early miscarriage, followed by five total live births, an abortion (between live births three and four) and a stillbirth. Immediately after giving birth, she enters the postpartum period, where she experiences some biological and behavioral changes, including reduced likelihood of sexual activity, breastfeeding, possible LAM, and new contraceptive choice probabilities.
Data sources and methods for parameter estimates
Depending on the parameter, agents are assigned probabilities based on a combination of any of the following: (1) context-specific probabilities applied uniformly; (2) age-specific probabilities; and/or (3) life-stage-specific probabilities. Table A1 in the Supplementary Materials lists the parameters and events that are possible for agents to experience in FPsim, as well as their respective data sources for the Senegal calibration. Note that these example data sources are meant to be informative for future calibrations, but because FPsim is data-driven and context-specific, different data sources are likely to be used for different scenarios. For instance, we parameterize matrices for initiating, discontinue, or switching contraceptive methods for Senegal using the Demographic and Health Survey (DHS) contraceptive calendars; but we use the Performance Monitoring in Action (PMA) calendars for Kenya (ICRHK 2022). Details on these matrices are in the section titled ‘Contraceptive choice’. Because no one data source captures all of the intricacies and nuances within a specific country or region, FPsim calibrations are best interpreted as country- or region-like (i.e., a Senegal-like setting).
Fecundability
Although it is commonly cited that 85% of women using no method will conceive within a year42, the biological underpinnings of fertility vary over the life course, following an inverted u-shaped curve as women age. Because we simulate an entire life course, age-specific fecundability estimates are critical inputs to FPsim. We parameterize fecundability as a linear interpolation of the percentage of women at each age who achieved pregnancy in the PRESTO study29,43. The PRESTO study is a prospective cohort study of couples seeking pregnancies in the United States and Canada. In addition to age-specific fecundability, as women age and do not conceive, they exhibit a further decreased likelihood of conceiving28. Thus, we use additional estimates from the PRESTO study to inform a separate parameter which adjusts individual women’s fecundability downward as they age and have yet to conceive.
Women under the age of 20 are not included in the PRESTO study. Fecundability is understudied in adolescents, with rare exceptions (see, for example44] on the relationship between undernutrition and married adolescent fecundability in Bangladesh). For the parameter in FPsim, we imputed fecundability at age 15 by applying the ratio of fertility rates for 15–19-year-olds compared to 25-year-olds. We then assume that fecundability is approximately linear from age 10 to 15 years old, as well as from age 15 to 20. The resulting distribution of age-specific fecundability estimates is shown in Fig. 3.

This panel shows the fecundability parameter estimates by age. These estimates indicate the probability of conceiving in a 12-month period. Each individual also receives an individual variation multiplier, which can bring fecundability up or down across her life course, to represent the real-life individual heterogeneity in underlying capacity to conceive. The shaded area represents the full range of possible fecundability curves.
In addition, individuals vary widely in their fecundability. To account for this individual-level heterogeneity, we introduce a multiplier for each agent—regardless of their age-specific base fecundability or their nulliparous adjustment, we multiply their final fecundability by the individual multiplier. For the Senegal context, we use the range 0.7–1.1, as this provided the best fit for the overall population. This means that some women consistently have much lower fecundability than the PRESTO estimate for their age, and some have slightly higher.
Infertility and fecundability may vary from context to context, particularly under conditions of extreme stress45. However, very few studies examine fecundability in lower- and middle-income countries, despite estimates that nearly 186 million women in LMICs experience primary or secondary infertility46. To our knowledge, there have been no prospective cohort studies on fecundability in sub–Saharan Africa to date. Because age-specific fecundability (the biologic capacity to conceive, not fertility) is rarely studied in countries with DHS surveys, we use these baseline fecundability values despite their limitations.
Contraceptive choice
Contraceptive choice in FPsim is parameterized through multiple age- and life-stage-specific choice matrices. The matrices represent the probability of switching from a given method, including no method, (the columns of the matrix), to another method, including no method (the rows of the matrix). Because the matrices include “no method”, they capture initiation, switching, and discontinuation. The matrices are derived from contraceptive calendar data—in the case of Senegal, we use the Demographic and Health Survey (DHS) data from the most recent survey, and in the case of Kenya we use the longitudinal Performance Monitoring in Action (PMA) data, as the most recent DHS for Kenya is now nearly a decade old.
Agents access the annual matrices once per year, on the timestep that represents their individual birth month. Agents can only choose one method at a time, which aligns with data limitations in the field, but which does not necessarily reflect women’s concurrent usage. While in reality, women may well switch or discontinue differently based on shorter or longer periods of use, for the purpose of simplifying the model, we calculate only the annual probabilities of switching. The choice matrices are stratified by age group, as well as postpartum status.
Nine specific methods are included: withdrawal, condoms, the pill, injectables, implants, IUDs, female sterilization, “other modern” which includes emergency contraceptive and standard days method, and “other traditional”, which, in the DHS, encompasses any other method a respondent mentions. During their birth month, women in FPsim access the contraceptive matrices and choose a method for the year. A visual representation of one of the age-specific matrices from Senegal is shown in Fig. 4.

This figure represents the probabilistic contraceptive switching matrix for the 18–20 year age group in FPsim-Senegal. Each bar represents the probability of switching from 1 year to the next. The figure does not show the overwhelming probability of remaining a non-user, that is, the None-to-None category, which is ~80% for this age group. Salmon bars represent continuation of the same method. Green bars represent discontinuation from a given method to “None”, blue bars represent initiation of a new method, and purple bars represent switching probabilities between different kinds of methods.
After delivery, separate postpartum matrices are accessed, which were derived using data from postpartum women. A 1-month postpartum matrix is used to assess probability of initiating a method 1 month after birth, and a separate postpartum matrix is used at 6 months postpartum to assess the probability of starting a method or switching or discontinuing for women who initiated a method at 1 month postpartum. Subsequently, each woman re-enters the annual (non-postpartum) matrix at her next birth month timestep.
Conception
One of the key life events that women experience in FPsim is conception. In any given timestep (representing 1 month), women who are sexually active that month are eligible to conceive. Their initial probability of conception is constituted by their individual fecundability. This probability is adjusted by their contraceptive choice—if none, there is no adjustment. All other methods are assigned an efficacy value based on failure rates among sexually active women of reproductive age in 43 DHS countries47. Women who are within 6 months of delivery and exclusively breastfeeding have a probability of remaining amenorrheic and thus meeting criteria for the lactational amenorrhea method (LAM), which provides excellent protection against pregnancy48. We consider LAM separately from the method-specific contraceptive matrix due to these qualifying criteria. Most efficacy rates are currently calculated considering sexual activity broadly, but do not restrict their calculations to women who were sexually active in every given month of the study. The method efficacy rates, therefore, could be over-estimated in our model. If an agent is sexually active in a given month, she is eligible to conceive, and we “check” conception. Due to reliability issues, we only consider sexual activity as an eligibility criterion and not as a direct factor that impacts the likelihood of successful conception. Conception is a function of both an agent’s individual fecundability as well as the efficacy of her contraceptive method of choice Thus, being sexually active in a given month unlocks the possibility of conception, but the probability of conception is determined by individual factors and contraception. For instance, a 25-year-old nulliparous agent in a Senegal-like setting who was sexually active this month will have an age-specific base fecundability of 0.793 and a nulliparous (life stage) adjustment of 0.96. She has also been assigned a random variation multiplier between 0.7 and 1.1—let us assume 0.8 for this hypothetical FPsim agent. Her total fecundability is the sum of 0.793 * 0.96 * 0.8 = 0.609. In the binomial trial to check conception, if the random number generated is lower than 0.609, this agent would conceive. However, if she also uses a modern contraceptive method, like the pill, then we apply another multiplier—(1-efficacy)—to her conception probability. In this case, her initial fecundability would be further reduced to 0.609 * (1 − 0.945) = 0.0335. Now this agent has greatly reduced chance (3.35%) of conception over the course of her year on the pill, which is converted to per-month probability. She will only conceive if the random number generated is lower than her individual probability in that timestep.
Pregnancy loss and mortality
During the same timestep that agents conceive, they have a probability of terminating the pregnancy, parameterized based on Guttmacher’s context-specific abortion incidence estimates49,50. If the pregnancy is not terminated, women may experience a miscarriage at the end of the first trimester (after 3 months gestation). Miscarriage probabilities are based on women’s age, where the youngest (<15) and the oldest (>35) have the highest risk. Pregnant women who are 25 years old have the lowest miscarriage probability, at 9.7%51. Once the gestation counter reaches the 9th month, women experience delivery. At the point of delivery, probabilities of live birth, including twins52, stillbirth, infant mortality, and maternal mortality are assessed, in that order. Both stillbirths and infant mortality estimates follow a time-trend based on annual country-level incidence53,54. Adolescents under 20 years old have a higher probability of experiencing both stillbirth and infant mortality, reflected in odds ratios calculated by Noori et al.55.
Maternal mortality ratio (MMR) is a notoriously difficult measure to estimate with any certainty, and indeed the World Bank reports a wide 80% confidence interval in addition to their point estimates. For the Senegal calibration, we opted for published estimates of the risk of maternal death in Mali and Senegal56. Because those estimates are based on institutional deliveries, we provide the confidence interval to allow users to select high, medium, and low estimates of maternal mortality. The baseline estimates from Huchon et al.56 are then extrapolated to create a time trend based on the annual change in the World Bank indicator for MMR57. No equivalent study of maternal death was available for Kenya, to our knowledge, and thus we use World Bank modeled estimates for Kenya’s maternal death probabilities. Because of the wide uncertainty range and the well-known issues with collecting maternal mortality data, this indicator should be interpreted with caution.
Data gaps and assumption-based parameters
One of the most informative aspects of a data-driven agent-based model is that researchers are forced to precisely indicate and quantify relationships between agents, agent history, and the agent’s environments. In doing so, the model development itself can highlight critical data gaps in the field. Insights into those critical data gaps can inform investments in data collection and programs. Although we leverage multiple data sources in FPsim, we do identify data gaps, for which we have used assumption-based parameters.
One of the most impactful of these assumptions, exposure, is a multiplier applied directly to conception probabilities, based on women’s age and/or parity, to proxy residual exposure to pregnancy not captured by data. For the Senegal calibration, we found that using age-based exposure was not necessary. However, we did find it necessary to use parity-based exposure to reduce the likelihood of conception once women reach parity 7 and above. In contexts with scarce data, researchers may find that exposure corrections, especially at the margins, are necessary to achieve realistic pregnancy outcomes.
Birth spacing patterns present a unique challenge to simulating synthetic cohorts. In part, this is due to mismatching data timelines for most demographic surveys (including the DHS). Contraceptive calendar data typically captures 1–5 years retrospectively, but shouldn’t be considered reliable much more than 12–24 months due to recall bias58. On the other hand, fertility data, in which respondents typically report birth month and year of each living child, spans a woman’s entire reproductive life course up to the time of interview. This creates a gap in knowledge where researchers can identify birth spacing between births for which we do not know that woman’s contraceptive use or non-use. Because of this gap, we developed a birth spacing preference parameter, which increases or decreases an agent’s likelihood of being sexually active while she is postpartum. This parameter indirectly impacts her likelihood of conception, via her eligibility each timestep.
Calibration and additional modules
We have built FPsim to be as modular and easy to use as possible. Calibrating to a new context requires a great deal of context-specific data. The public repository for FPsim contains all files necessary to process these data. Parameterizing the model is relatively straightforward, and researchers can follow the templates created by the authors’ efforts to calibrate to Senegal and Kenya.
In addition, researchers may find that their questions are not entirely represented by the list of outcomes and related dynamics that FPsim currently uses. In those cases, users can create their own modules within FPsim. This can be as simple as adding odds ratios to outcomes, such as increased probabilities of experiencing adverse outcomes for the youngest mothers under the age of 15, or the impact of assisted reproductive technology on individual fecundability. On the other end of the spectrum, modifications could be as complicated as creating new distributions of educational attainment that can be interrupted or delayed by pregnancy and childbirth in adolescence, for instance. While the former can be achieved with a few lines of code, the latter will require more advanced researcher experience with agent-based modeling in Python to achieve. As with many models, we anticipate ongoing, user-driven development of FPsim.
Results
Using FPsim for research
Given a set of basic biological constraints (fecundability, conception, pregnancy), we can use FPsim to model the impact of dynamic individual-level decisions about contraceptive use and/or shifting probabilities of pregnancy-related events (e.g., abortion) on specified metrics over time. How we use FPsim depends on what kind of information we have, and generally fall under one of two categories: data-driven research questions, and assumption-based research questions.
Data-driven research questions leverage additional data sources, including historical datasets, user insights and market research, and so on, to inform how we anticipate behavioral changes for some women. For instance, some research questions might investigate the compounding effects over time of increased uptake of a specific method. With FPsim, we could also examine those effects if the changes are limited to specific age groups, or postpartum women. We can investigate how switching behaviors impact the roll-out of a new contraceptive method. For example, a researcher may want to compare scenarios in which we roll out a new injectable and a new implant in a Senegal-like setting where contraceptive prevalence is low; but amongst method users, injectables and implants are already popular. We could examine how investing in an improved injectable or implant might impact the method mix and other family planning outcomes. Identifying and quantifying data gaps would also fall under data-driven research questions.
Assumption-based research, on the other hand, implements user-defined assumptions into the model to reach particular outcomes. The researcher may ask, for example, what magnitude of behavioral change (uptake) would have needed to occur to meet FP2020 mCPR goals in a certain country? Another example of an assumption-based question would be what kind of gains in adolescent postpartum family planning would need to occur to reduce rapid repeat pregnancies, and in turn, adolescent maternal mortality.
Scenarios
To examine any research question using FPsim, the model needs to be calibrated to a setting, either a pre-programmed setting like Kenya or Senegal, or a custom calibration that users create for their own research questions. Once the model is calibrated, custom intervention scenarios can be built to investigate a wide range of research questions. Users can adjust nearly any parameter with the built-in scenarios script, including abortion, the probabilities of adverse outcomes (e.g., stillbirth), and the dimensions of any existing method (such as efficacy, initiation, switching to another method, and discontinuation). Users can also add a new contraceptive technology by adding in a row and method to the existing contraceptive matrices. These scenarios can be built to affect an entire population, or they can be written to affect specific sub-populations, which may be defined by characteristics including age, parity, or postpartum status.
FPsim allows for straightforward, user-friendly scenario-building. The following example scenarios are intended to illustrate the mechanics of building scenarios in FPsim, rather than to answer any one specific research question. In the first example, we build hypothetical scenarios for FPsim-Senegal, in which we (1) increase the efficacy of existing injectable methods to 99%; (2) double the probability of all women initiating injectables; (3) double the probability of women over 35 initiation injectables; and (4) combine scenarios 1 and 3, increasing the efficacy of injectables for all, and doubling the initiation for women over the age 35. Figure 5 displays the code snippet used to build the scenarios.

The figure shows an image of real FPsim code that generates simple scenarios in the model. The code begins with importing the model. Next, the parameters that will be used repeatedly through the scenarios are set, including some short-hand to capture parameters that users may not want to write out each time (e.g., youth = [“<18”, “18–20”]). The code then calls the parameters into a list and adds a new parameter which represents a new method that will be added to the matrix. Next, the code sets up four simple scenarios (s1, s2, s3, and s4) which concern hypothetical adjustments to existing injectable methods.
Full python scripts to replicate the scenarios and outputs of these sample scenarios are publicly available at: https://github.com/fpsim/fpsim_technical.
More complex scenarios, to add in a new contraceptive technology, for instance, take a slightly different shape. In the example below, we are building a single scenario in three distinct parts. Figure 6 contains the code snippet to build this three-part scenario.

The figure builds off of Fig. 5 by introducing more complex scenarios which add in the new method we defined in Fig. 5. This code uses dictionaries to build scenarios with multiple adjustments made, including introducing the new method, assigning a probability of initiating, anticipating switching from the old method, and targeting a sub-population for increased initiation.
In part a, we first introduce the new injectable method by copying over characteristics from the existing injectable (dict(copy_from=’Injectables’, method=method, ages=limiters)). We then identify the characteristics we want to change for the named age group, limiters, who are over 35. In this case, we want to halve the discontinuation probability for the newly introduced injectables (discont_factor=0.5), perhaps assuming the new injectables will address issues like side effects and be more appealing to women than the existing method. In part b, we anticipate 20% probability of switching from existing injectables to the new injectables. In part c, we add in a staggered introduction that focuses on the youth (under 20) population. As before, we simply add up the three scenario parts to incorporate all aspects of our new contraceptive technology into a single scenario.
Output
FPsim has integrated plot options that can be utilized after a single sim or after a multiple simulation run with user-defined scenarios. The default plotting option (plot()) includes mCPR, a cumulative count of live births, stillbirths, maternal deaths, and infant deaths, and the infant mortality rate. Figure 7 shows the default output for our basic set of sample scenarios.

This figure shows the six-panel default output that is produced in FPsim. The panels show, from left to right, modern contraceptive prevalence rate (%), count of live births, count of stillbirths, count of maternal deaths, count of infant deaths, and the infant mortality rates for the entire run of the model, 1980–2030. The blue line represents the baseline, and the rest of the lines are the various scenarios. The highest mCPR occurs in the scenario where injectable initiation is doubled for all ages (green line). Because FPsim allows us to repeat the same scenario multiple times, we are able to plot confidence intervals, which are shown in the shaded areas. The largest confidence intervals (and greatest uncertainty) are shown for maternal deaths, consistent with the real-life uncertainty around measurements of maternal mortality.
Other integrated plotting options include adverse pregnancy outcomes, multiple definitions of contraceptive prevalence, and method mix over time. Figure 8 shows the method mix plotting of our more complex scenario, in which we may want to track the how the switching patterns we identified impact the existing injectables (light blue) when we introduce the new injectables (salmon).

This figure shows the baseline method mix (top panel) versus a new scenario in which we introduce new injectables to the context (bottom panel). The new method is represented by the salmon color and is introduced in 2020. In the decade after the method is introduced in the simulated scenario, mCPR gains 5 percentage points over the baseline, even while other methods (IUDs in dark purple, implants in light purple) stagnate and even decline (e.g., old injectables in turquoise).
Discussion
Although there currently exist FP models that provide cross-country comparisons, we see a need for an FP model designed to explicitly consider individual trajectories, to complement and augment our understanding of the conditions under which family planning programs succeed or fail. With a focus on macro-level inputs and outputs alone, we risk missing the individual heterogeneity in biology and behavior, that underlie and can deeply impact family planning dynamics at both the micro- and macro-levels. We designed Family Planning Simulator (FPsim), which centers a woman’s individual life course. This allows FPsim to generate insights into how individual behavior and biology impact fertility and health outcomes, including contraceptive prevalence, pregnancy loss and mortality, and method mix. With individual-level modeling and a life course perspective, we can better capture how probabilistic behaviors interact with biology, and how events and activities impact women differently throughout their life. FPsim provides an agent-based environment in which researchers can leverage multiple sources of data and interrogate assumptions. Researchers and policymakers alike can use the tool to improve goal setting through examining behavioral change—i.e., changing demand—rather than relying on supply-side factors alone. FPsim’s flexible and modular simulation scenarios provide an opportunity to explore the impact of policies and investments in family planning using a modeling tool designed around a woman’s unique reproductive life course.
To that end, we hope that FPsim can be used by computational scientists as well as users with no experience in computational modeling. Quick scenarios can be developed for government officials and policymakers, while more involved scenarios can be used in-house to better anticipate the potential outcomes of specific investments of global health NGOs. In developing FPsim, we aimed to create a simple, straightforward, and easy to use model, that could be widely applicable to many different contexts.
As with any computational modeling methodology, FPsim has its limitations. No simulation model can replace rigorous data collection and analysis. The insights that FPsim produces are only as good as the inputs and expertise that inform the model. FPsim is best used as a tool to ask questions about what could be, or what could have been, using counterfactual scenarios informed by robust data and expert opinion. Currently, we have focused on high fertility settings that have DHS or PMA data. Researchers in contexts with different data sources (including Health and Demographic Surveillance Sites) may find it more difficult to calibrate to those settings and may need to expand the model itself to accommodate surveillance-style data. With these caveats, we aim for FPsim to be a user-friendly and informative tool that can supplement the family planning research and evaluation landscape to help decision-makers better target the most impactful investments, programming, and implementation strategies.
Methods
FPsim was developed in Python using the SciPy (scipy.org) ecosystem. It uses NumPy (numpy.org), Pandas (pandas.pydata.org), and Numba (numba.pydata.org) for fast numerical computing; Matplotlib (matplotlib.org) for plotting; and Sciris (sciris.org) for data structures, parallelization, and other utilities. Source code for FPsim is available via both the Python Package Index (via pip install fpsim) and GitHub (via fpsim.org).
Data availability
All material necessary to replicate the figures in this paper, including source code and minimal aggregate data arrays, are publicly available at https://github.com/fpsim/fpsim_technical. Microdata from the Demographic and Health Surveys is free of charge, but requires permission to access, which can be requested at www.dhsprogram.com.
References
Chola, L., McGee, S., Tugendhaft, A., Buchmann, E. & Hofman, K. Scaling up family planning to reduce maternal and child mortality: the potential costs and benefits of modern contraceptive use in South Africa. PLoS ONE 10, e0130077 (2015).
Cleland, J., Conde-Agudelo, A., Peterson, H., Ross, J. & Tsui, A. Contraception and health. Lancet 380, 149–156 (2012).
Rana, M. J. & Goli, S. Does planning of births affect childhood undernutrition? Evidence from demographic and health surveys of selected South Asian countries. Nutrition 47, 90–96 (2018).
Rana, M. J. & Goli, S. The road from ICPD to SDGs: health returns of reducing the unmet need for family planning in India. Midwifery 103, 103107 (2021).
Singh, S., Darroch, J. E. & Ashford, L. S. Adding It Up: The Costs and Benefits of Investing in Sexual and Reproductive Health 2014 (UN Population Fund, 2014).
Dhak, B., Saggurti, N. & Ram, F. Contraceptive use and its effect on Indian women’s empowerment: evidence from the National Family Health Survey-4. J. Biosoc. Sci. 52, 523–533 (2020).
Prata, N. et al. Women’s empowerment and family planning: a review of the literature. J. Biosoc. Sci. 49, 713–743 (2017).
Brunson, J. Tool of economic development, metric of global health: promoting planned families and economized life in Nepal. Soc. Sci. Med. 254, 112298 (2020).
Speizer, I. S., Bremner, J. & Farid, S. Language and measurement of contraceptive need and making these indicators more meaningful for measuring fertility intentions of women and girls. Glob. Health Sci. Pract. 10, e2100450 (2022).
Barham, T. et al. Thirty-five years later: long-term effects of the Matlab maternal and child health/family planning program on older women’s well-being. Proc. Natl Acad. Sci. 118, e2101160118 (2021).
Brunson, J. & Suh, S. Behind the measures of maternal and reproductive health: ethnographic accounts of inventory and intervention. Soc. Sci. Med. 254, 112730 (2020).
Finlay, J. E. & Lee, M. A. Identifying causal effects of reproductive health improvements on women’s economic empowerment through the population poverty research initiative. Milbank Q. 96, 300–322 (2018).
Okenwa, L., Lawoko, S. & Jansson, B. Contraception, reproductive health and pregnancy outcomes among women exposed to intimate partner violence in Nigeria. Eur. J. Contracept. Reprod. Health Care 16, 18–25 (2011).
Schwarz, J. et al. So that’s why I’m scared of these methods’: locating contraceptive side effects in embodied life circumstances in Burundi and eastern Democratic Republic of the Congo. Soc. Sci. Med. 220, 264–272 (2019).
Railsback, S. F. & Grimm, V. Agent-Based and Individual-Based Modeling: A Practical Introduction (Princeton University Press, 2012).
Billari, F., Fent, T., Prskawetz, A. & Aparicio Diaz, B. The ‘Wedding-Ring’: an agent-based marriage model based on social interaction. Demogr. Res. 17, 59–82 (2007).
Bonabeau, E. Agent-based modeling: methods and techniques for simulating human systems. Proc. Natl Acad. Sci. 99, 7280–7287 (2002).
Silverman, E. et al. Situating agent-based modelling in population health research. Emerging Themes in Epidemiology. 18(1), 10 (2021).
Bijak, J., Hilton, J., Silverman, E. & Cao, V. D. Reforging the wedding ring: exploring a semi-artificial model of population for the United Kingdom with Gaussian process. Demogr. Res. 29, 729–766 (2013).
An, L. & Liu, J. Long-term effects of family planning and other determinants of fertility on population and environment: agent-based modeling evidence from Wolong Nature Reserve China. Popul. Environ. 31, 427–459 (2010).
Kashyap, R. & Villavicencio, F. An agent-based model of sex ratio at birth distortions. In Agent-Based Modelling in Population Studies: Concepts, Methods, and Applications, Vol. 41 (eds Grow, A. & Van Bavel, J.) 343–367 (Springer International Publishing, 2017).
Williams, N. E., O’Brien, M. L. & Yao, X. Using survey data for agent-based modeling: design and challenges in a model of armed conflict and population change. in Agent-Based Modelling in Population Studies: Concepts, Methods, and Applications (eds Grow, A. & Van Bavel, J.) 159–184 (Springer International Publishing, 2017).
Williams, N. E., O’Brien, M. L. & Yao, X. How armed conflict influences migration. Popul. Dev. Rev. https://doi.org/10.1111/padr.12408 (2021).
Hinsch, M. & Bijak, J. Principles and state of the art of agent-based migration modelling. in Towards Bayesian Model-Based Demography: Agency, Complexity and Uncertainty in Migration Studies (ed. Bijak, J.) 33–49 (Springer International Publishing, 2022).
Karra, M., Canning, D. & Wilde, J. The effect of fertility decline on economic growth in Africa: a macrosimulation model. Popul. Dev. Rev. 43, 237–263 (2017).
Smarr, M. M. et al. Is human fecundity changing? A discussion of research and data gaps precluding us from having an answer. Hum. Reprod. https://doi.org/10.1093/humrep/dew361 (2017).
Steiner, A. Z. et al. Antimüllerian hormone as a predictor of natural fecundability in women aged 30–42 years. Obstet. Gynecol. 117, 798–804 (2011).
Steiner, A. Z. & Jukic, A. M. Z. Impact of female age and nulligravidity on fecundity in an older reproductive age cohort. Fertil. Steril. https://doi.org/10.1016/j.fertnstert.2016.02.028 (2016).
Wesselink, A. K. et al. Age and fecundability in a North American preconception cohort study. Am. J. Obstet. Gynecol. https://doi.org/10.1016/j.ajog.2017.09.002 (2017).
Ajzen, I. & Klobas, J. Fertility intentions: an approach based on the theory of planned behavior. Demogr. Res. 29, 203–232 (2013).
Bongaarts, J. & Casterline, J. B. From fertility preferences to reproductive outcomes in the developing world. Popul. Dev. Rev. 44, 703–809 (2018).
Cottingham, J. Beyond acceptability: users’ perspectives on contraception. in Beyond Acceptability: Users’ Perspectives on Contraception (eds Ravindran, T. K. S., Berer, M. & Cottingham, J.) 1–5 (Reproductive Health Matters for the World Health Organization, 1997).
Preis, H. et al. Fertility intentions and the way they change following birth—a prospective longitudinal study. BMC Pregnancy Childbirth 20, 228 (2020).
Bledsoe, C., Banja, F. & Hill, A. G. Reproductive mishaps and western contraception: an African challenge to fertility theory. Popul. Dev. Rev. 24, 15–57 (1998).
Habbema, J. D. F., Eijkemans, M. J. C., Leridon, H. & te Velde, E. R. Realizing a desired family size: when should couples start? Hum. Reprod. 30, 2215–2221 (2015).
Leridon, H. Can assisted reproduction technology compensate for the natural decline in fertility with age? A model assessment. Hum. Reprod. 19, 1548–1553 (2004).
Stover, J., McKinnon, R. & Winfrey, B. Spectrum: a model platform for linking maternal and child survival interventions with AIDS, family planning and demographic projections. Int. J. Epidemiol. 39, i7–i10 (2010).
Weinberger, M., Pozo-Martin, F., Boler, T., Fry, K. & Hopkins, K. Impact 2 v5: An Innovative Tool for Estimating the Impact of Reproductive Health Programmes: Methodology Paper. (Marie Stopes International, London, 2012).
Cahill, N. et al. Modern contraceptive use, unmet need, and demand satisfied among women of reproductive age who are married or in a union in the focus countries of the Family Planning 2020 initiative: a systematic analysis using the Family Planning Estimation Tool. Lancet 391, 870–882 (2018).
Adetunji, J. & Feyisetan, B. Stages in the adoption of modern contraceptive methods: do the growth patterns in developing countries follow the S-Curve model? Population Associatoin of America 2017 Annual Meeting (2017).
Mercer, L. D., Lu, F. & Proctor, J. L. Sub-national levels and trends in contraceptive prevalence, unmet need, and demand for family planning in Nigeria with survey uncertainty. BMC Public Health 19, 1752 (2019).
Trussell, J. Contraceptive failure in the United States. Contraception 83, 397–404 (2011).
Wise, L. A. et al. Design and conduct of an internet-based preconception cohort study in North America: pregnancy study online (PRESTO). Paediatr. Perinat. Epidemiol. 29, 360–371 (2015).
Hur, J. et al. Thinness and fecundability: time to pregnancy after adolescent marriage in rural Bangladesh. Matern. Child. Nutr. 16, e12985 (2020).
Wesselink, A. K. et al. Perceived stress and fecundability: a preconception cohort study of North American couples. Am. J. Epidemiol. https://doi.org/10.1093/aje/kwy186 (2018).
Mascarenhas, M. N., Flaxman, S. R., Boerma, T., Vanderpoel, S. & Stevens, G. A. National, regional, and global trends in infertility prevalence since 1990: a systematic analysis of 277 health surveys. PLoS Med. 9, e1001356 (2012).
Polis, C. B. et al. Contraceptive Failure Rates in the Developing World. https://doi.org/10.1016/j.contraception.2016.03.011 (2016).
Van der Wijden, C. & Manion, C. Lactational amenorrhoea method for family planning. Cochrane Database Syst. Rev. 2015, CD001329 (2015).
Sedgh, G., Sylla, A. H., Philbin, J., Keogh, S. & Ndiaye, S. Estimates of the incidence of induced abortion and consequences of unsafe abortion in Senegal. Int. Perspect. Sex. Reprod. Health. https://doi.org/10.1363/4101115 (2015).
Mohamed, S. F. et al. The estimated incidence of induced abortion in Kenya: a cross-sectional study. BMC Pregnancy Childbirth 15, 185 (2015).
Magnus, M. C., Wilcox, A. J., Morken, N. H., Weinberg, C. R. & Håberg, S. E. Role of maternal age and pregnancy history in risk of miscarriage: prospective register based study. BMJ Online. https://doi.org/10.1136/bmj.l869 (2019).
Smits, J. & Monden, C. Twinning across the developing world. PLoS ONE 6, e25239 (2011).
UN Inter-agency Group for Child Mortality Estimation. A Neglected Tragedy: The Global Burden of Stillbirths. https://childmortality.org/wp-content/uploads/2020/10/UN-IGME-2020-Stillbirth-Report.pdf (2020).
World Bank. Infant Mortality Rate (World Bank, 2019).
Noori, N., Proctor, J. L., Efevbera, Y. & Oron, A. P. The Effect of Adolescent Pregnancy on Child Mortality in 46 Low- and Middle-Income Countries. http://medrxiv.org/lookup/doi/10.1101/2021.06.10.21258227; https://doi.org/10.1101/2021.06.10.21258227 (2021).
Huchon, C. et al. A prediction score for maternal mortality in Senegal and Mali. Obstet. Gynecol. 121, 1049–1056 (2013).
WHO, UNICEF, UNFPA, World Bank Group, & United Nations Population Division. Trends in Maternal Mortality: 2000 to 2017 (World Health Organization, Geneva, 2019).
Callahan, R. L. & Becker, S. The reliability of calendar data for reporting contraceptive use: evidence from rural Bangladesh. Stud. Fam. Plann. 43, 213–222 (2012).
Acknowledgements
The authors would like to thank all those who provided helpful feedback during both the model-building and manuscript writing phases of this work, including Leontine Alkema, Anne Biddlecom, Jamaica Corker, Lucas Godoy Garraza, Mandy Izzo, Agnes Kiragga, Anu Mishra, Boniface Ushie, Yohannes Dibaba Wado, and Kirsten Vogelsong. Earlier versions of this work benefitted from the Computational Demography session at the Population Association of America, as well as the International Conference on Family Planning. Two anonymous reviewers were critical in providing helpful comments and suggestions throughout the review process.
Author information
Authors and Affiliations
Contributions
M.L.O. and A.V. wrote the main manuscript text. C.C.K., D.J.K., G.C., J.L.P., H.O., and M.Z. conceptualized and designed the model architecture. M.L.O., A.V., C.C.K., D.J.K., M.Z., S.B., and N.N. contributed code to build the model. M.L.O., A.V., C.C.K., and D.J.K. calibrated the model. M.L.O., A.V., H.O., G.C.C., J.L.P., E.D.R., and M.Z. provided additional subject matter expertise.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
O’Brien, M.L., Valente, A., Kerr, C.C. et al. FPsim: an agent-based model of family planning. npj Womens Health 1, 1 (2023). https://doi.org/10.1038/s44294-023-00001-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s44294-023-00001-z
