
Abstract
Orthohantaviruses infect distinct eulipotyphlan and rodent reservoirs throughout the world; some rodent orthohantaviruses can cause disease in humans. In the United States, a primary rodent reservoir for the human-pathogenic Sin Nombre virus (SNV) is the western deermouse (Peromyscus sonoriensis; formerly included in Peromyscus maniculatus). Deermice (rodents of genus Peromyscus) carry presumably distinct orthohantaviruses but, although deermice of ten species have been recorded in New Mexico, only SNV has been reported in rodents from that state. Using a set of pan-orthohantavirus primers, we discovered a non-SNV orthohantavirus in a brush deermouse (P. boylii), trapped in central New Mexico in 2019. Sequencing enabled the generation of a consensus coding-complete genome sequence, revealing similarity to the known partial sequences of the unclassified “Limestone Canyon virus (LSCV)” in GenBank and aligning with the information in an unpublished study of wild-caught brush deermice trapped in southwestern New Mexico in 2006. Phylogenetic analysis of these combined data revealed geospatial clades and overall identity of “LSCV”, uncovering its association with the classified Montaño virus (MTNV), which is known to infect Aztec and Orizaba deermice in central Mexico. Our work emphasizes the importance of determining coding-complete viral genome sequences as a framework for rigorous virus classification as the basis for epidemiological studies.
Similar content being viewed by others

Introduction
Hantaviridae is a bunyaviral family of trisegmented, enveloped, negative-sense RNA viruses that globally infect a wide range of hosts, including fish, reptiles, and mammals. Mammalian hantavirids are classified across four genera in the subfamily Mammantavirinae. Mammantavirins pathogenic for humans are rodent-borne viruses of genus Orthohantavirus1.
The first identified hantavirid, the orthohantavirus Hantaan virus (HTNV), was described in 1976 in striped field mice (Murinae: Apodemus agrarius (Pallas, 1771)) and identified as an etiologic agent of human “epidemic hemorrhagic fever” in (South) Korea2,3. Later identified in Asia and Europe were at least another ten orthohantaviruses that can cause the same disease4, now designated hemorrhagic fever with renal syndrome (HFRS; International Classification of Diseases 11th Revision [ICD-11] Code 1D62.0)5. All of these viruses are hosted by one or several distinct rodents4. The first identified American hantavirid, the nonpathogenic orthohantavirus Prospect Hill virus (PHV), was found in meadow voles (Arvicolinae: Microtus pennsylvanicus (Ord, 1815)) in Maryland in 19826. This finding was followed by the discovery of Sin Nombre virus (SNV) in western deermice (Neotominae: Peromyscus sonoriensis (J. A. Wagner, 1845); recently split from P. maniculatus7) in the Four Corners region of the United States in 1993; SNV was quickly identified as the etiologic agent of a novel, severe, and often fatal human disease8,9 now designated hantavirus pulmonary syndrome (HPS; ICD-11 Code 1D62.1)5. Subsequently, ≈25 orthohantaviruses endemic to the Americas have been affiliated with HPS4, most notably Andes virus of long-tailed colilargos (Sigmodontinae: Oligoryzomys longicaudatus (Bennett, 1832)) in South America10,11. Currently, genus Orthohantavirus includes 38 species for 60 classified viruses12; more than 70 putative orthohantaviruses remain to be classified13.
Originally, distinct orthohantaviruses were hypothesized to be carried by and to co-evolve with distinct rodent hosts, but this school of thought has eroded considerably over recent years1,14,15,16,17,18,19. For instance, SNV may be maintained by rodents of multiple species, including least chipmunks (Sciuridae: Neotamias minimus (Bachman, 1839)), brush deermice (Peromyscus boylii (Baird, 1855)), and house mice (Murinae: Mus musculus Linnaeus, 1758) in addition to western deermice20,21. Seroprevalence studies have found anti-SNV antibodies in Piñon deermice (Peromyscus truei (Shufeldt, 1885)) and cactus deermice (Peromyscus eremicus (Baird, 1858))22,23. In addition, deermice of multiple species can be experimentally infected with SNV, with white-footed deermice (Peromyscus leucopus (Rafinesque, 1818)) developing higher viral and antibody titers than western deermice24. These findings indicate that incompletely characterized orthohantaviruses, which were given distinct names solely based on their “unique” rodent association and hence geographic distribution, may actually be known (and classified) orthohantaviruses. Intensive temporal and spatial surveillance efforts across diverse host communities, especially in areas of sympatry where multiple populations interact and may generate reassortant viruses, are needed for increased understanding of orthohantavirus ecology, evolution, and zoonotic potential25,26.
In the southwest region of the United States, including New Mexico, multiple Peromyscus species are syntopic, providing excellent opportunities to discover novel orthohantaviruses and study their ecology and evolution27,28,29. Coding-complete sequencing of orthohantavirus genomes assists with surveillance efforts30,31,32 and enables rigorous virus identification, taxonomic assignment33, and investigations of evolutionary processes (e.g., reassortment, phylodynamics). Using a pan-orthohantavirus real-time reverse transcription polymerase chain reaction (RT-qPCR) assay30 we surveyed deermouse populations throughout New Mexico and found a brush deermouse with a non-SNV orthohantavirus infection. Initial partial sequencing indicated the virus to be the unclassified “Limestone Canyon virus (LSCV)”, which was initially described in 2001 in brush deermice in central Arizona via partial sequencing of the small (S) and medium (M) genomic segments34. Generation of coding-complete “LSCV” S, M, and large (L) segment sequences identified the virus as Montaño virus (MTNV; Orthohantavirus montanoense), previously only known to infect Orizaba deermice (Peromyscus beatae (Thomas, 1903)) and Aztec deermice (Peromyscus aztecus (Saussure, 1860)) in central Mexico35,36. Furthermore, we found MTNV prevalence in multiple locations across New Mexico, revealing geospatially distinct subclades.
Results
Identification of an orthohantavirus in a wild-caught brush deermouse (P. boylii) in New Mexico
In a previous study, we screened lung tissue of 100 wild-caught rodents captured in New Mexico to validate a novel pan-orthohantavirus RT-qPCR detection assay30. Using these primers to sequence amplified fragments of the S segment in the lungs of naturally infected wild-caught animals, we recovered a test-positive brush deermouse (MSB:Mamm:332771), trapped near a campground in Red Canyon, within the Manzano Mountains of central New Mexico (Table 1). The amplified 180-nucleotide (nt)-long sequence was 91.72% similar to the matching sequence of the 1,209-nt-long partial S segment sequence of “LSCV” in the National Center for Biotechnology Information (NCBI) GenBank database (#AF307322)34. Using a nested PCR assay against a hantavirid-conserved region of the L segment for hantavirids, we amplified and sequenced a 363-nt-long fragment with highest identity (79.19%) to MTNV (#AB620102), which has thus far only been described in samples from central Mexico35,36 (Fig. 1).

A maximum-likelihood tree using a General Time Reversible model was generated based on the partial nucleotide sequences of S segment (top) and L segment (bottom), using PanHS8 and Klempa primers, respectively. There are 1,000 bootstraps supported. MSB:Mamm:332771 (red) indicates potential “LSCV” fragment sequence. The tree was rooted to the Hantaan virus (HTNV) reference sequence. Additional orthohantavirus reference sequences were obtained through NCBI. Sin Nombre virus (control) refers to SNV-infected Vero E6 supernatant used as a positive control. The scale bar represents the number of nucleotide substitutions per site.
High-throughput sequencing (HTS) strategies have been increasingly utilized for viral identification and surveillance in host tissues50,51,52. Only recently have they been applied to orthohantaviruses, but low viral titers in host tissues pose difficulty for accurate sequencing and identification50. Due to the lack of a coding-complete “LSCV” genome sequence (available sequences only partially covered S and M sequences34,53,54), we conducted whole-genome sequencing (WGS) to assemble a coding-complete genome of the virus from MSB:Mamm:332771. Of 14,907,288 reads, 44,667 were virus-related, with 38,325 (85.8%) associated with orthohantaviruses. Top hits were (in descending frequency): MTNV (9,514—24.8%), Khabarovsk virus (KHAV; 6761—17.6%), SNV (3989—10.4%), Caño Delgadito virus (CADV; 1,263—3.3%), Fǔsōng virus (FUSV; 1274—3.3%), Rockport virus (RKPV; 913—2.4%), and HTNV (921—2.4%) (Supplemental Fig. 1). Interestingly, MTNV was the top hit for reads associated with L sequence fragment data generated with RT-qPCR (Fig. 1).
We filtered our trimmed reads to only those that binned to Hantaviridae. Next, we performed de novo sequence assembly and generated 18 nodes. Then, we screened each node using NCBI Basic Local Alignment Search Tool (NCBI BLAST), with eight nodes generating hits for hantavirids and contigs matching the MSB:Mamm:332771 virus genome sequence. Of the eight contigs, four formed the S segment (nucleoprotein coding region), one formed the M segment (coding region for the Gn/Gc glycoproteins), and three formed the L segment (coding region for the large protein with its RNA-directed RNA polymerase). Using MTNV (#AB620100–AB620102) as a reference genome guide due to similarities, S and L segment sequences appeared mostly complete after aligning contigs. The M segment sequence only contained 1,352 nt but was anticipated to be no less than 3489 nt (Supplemental Table 1). We aligned our sequence with the previously reported “LSCV” M segment sequence (#AF307323)34 and measured 92.97% nucleotide identity. Using the reported M segment sequence (#AF307323) and MTNV L segment fragment sequence (#AB620102), we optimized and re-designed primer sets (Supplemental Table 2) and Sanger-sequenced the missing parts of the M and L segments to generate a coding-complete sequence.
We verified the sequence from the WGS using an amplicon-based PCR tiling approach that has been frequently used to sequence orthohantavirus genomes21,31,32. We generated 19 different primer sets that overlapped and spanned the coding regions of the S, M, and L segments (Supplemental Table 2) based on the sequence we derived using WGS. Using MSB:Mamm:332771 lung tissue cDNA, we tested each primer set and amplified the entire coding region of the virus genome (Supplemental Fig. 2). Amplified products were purified and subjected to Sanger sequencing. We aligned the sequence fragments with the WGS-generated genome sequence and found 99.7% sequence homology. Any nucleotide disagreement was manually viewed to ensure nucleotide accuracy. This additional validation step assured a consensus genome for MSB:Mamm:332771 and the accuracy of our viral WGS approach. The final sequences were deposited to NCBI GenBank under accession numbers #OR148902–4.
Extension of partial orthohantavirus sequences in brush deermouse (P. boylii) specimens collected in southwestern New Mexico
In 2006, wild-caught rodents in Hidalgo and Grant counties in southwestern New Mexico were surveyed (Supplemental Table 3). Of the 88 deermice captured, brush deermice (P. boylii) accounted for ≈ 65% (57/88), along with ≈17% Piñon deermice (P. truei, 15/88), ≈16% cactus deermice (P. eremicus, 14/88), ≈1% western deermice (P. sonoriensis, 1/88), and ≈1% white-footed deermice (P. leucopus, 1/88). Serologically, 33 of the 88 mice had immunoglobulin G (IgG) antibodies that cross-reacted with SNV N antigen, whereas 16 of the 33 cross-reacted to Rio Mamoré virus (RIOMV) N antigen. Most positives were brush deermice (28 seropositive for SNV and 16 for RIOMV), whereas only four Piñon deermice and one cactus deermouse were seropositive for SNV.
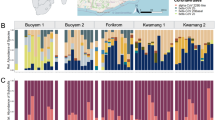
As previously described55, levels of seropositivity did not necessarily correlate with detection of viral genetic material, fragments of which were only detected in eight specimens of P. boylii by custom designed primers in an RT-PCR assay targeting the S segment. These specimens were acquired from three sites designated Site 1, Site, 2, and Site 3. Site 1 and Site 2 are ≈0.6 km apart, with a road between them, whereas Site 3 is located ≈8 km into the forest region near Burro Peak in the Big Burro Mountains. A 2019 sample (MSB:Mamm:332771) was collected in central New Mexico, whereas the previous study was conducted in the southwestern region of the state, roughly 400 km apart (Fig. 2). Partial M segment sequences could be generated from seven of these eight specimens. The S and M segment sequences diverged by 5.4–6.4% and 5.0–6.5% from the previously deposited “LSCV” S (#AF307322) and M (#AF307323) segment sequences34 (Table 1, Fig. 1).

Red markers indicate collection localities of specimens used for this study. Enlarged area shows multiple collection sites from 2006. Source: New Mexico map and Google maps.
To extend analysis of this virus in the samples collected in 2006, we retrieved lung tissues for the eight specimens from the University of New Mexico (UNM) Museum of Southwestern Biology (MSB) Division of Genomic Resources (DGR) biorepository and performed RT-qPCR. We successfully expanded the S segment sequences from ≈1200–1600 nt and the M segment fragments from ≈800–900 to ≈3000 nt We also generated partial L segment sequences for all eight rodents.
Geospatial clustering of orthohantavirus sequences in brush deermice (P. boylii)
Because the two studies were conducted in different regions of New Mexico, we analyzed the genetic similarity of the generated sequences against the “LSCV” fragments published previously from Arizona34, ≈574–716 km from the New Mexico sites, along with other previously reported fragments in GenBank53,54. We performed phylogenetic analysis to compare individual segments against known reference sequences of diverse hantavirids. All S segment sequences grouped under “LSCV”. Interestingly, we observed that samples from New Mexico clustered together, apart from fragments reported from Texas and Mexico. However, Site 1 and Site 2 sequences from the 2006 study clustered separately. The initial “LSCV” fragment from Arizona was most similar to sequences from New Mexico than to those from Texas or Mexico (Fig. 3). The “LSCV” M segment sequences repeated this pattern; Site 1 and Site 3 clustered apart from Site 2 sequences. The 2019 MSB:Mamm:332771 sequence clustered with New Mexico sequences (Fig. 4).

A maximum-likelihood tree was generated using a General Time Reversible model based on nucleotides of the S segment (nucleocapsid coding region) of multiple reported sequences of orthohantaviruses. There are 1,000 bootstraps supported. MSB:Mamm:332771 (red) indicates reference genome generated. Samples from New Mexico formed a monophyletic clade composed of two subclades, delineating further geographic structure and containing samples from Site 1 (blue), Site 2 (green), and Site 3 (gold). Additional orthohantavirus reference sequences were obtained through NCBI. The scale bar represents the number of nucleotide substitutions per site. US United States, MX Mexico, TX Texas, SLP San Luis Potosí, NL Nuevo León, EM State of Mexico, AZ Arizona, NM New Mexico.

A maximum-likelihood tree was generated using a General Time Reversible model based on nucleotides of the M segment (glycoproteins Gn/Gc coding region) of multiple reported sequences of orthohantaviruses. There are 1,000 bootstraps supported. MSB:Mamm:332771 (red) indicates reference genome generated. Samples from New Mexico formed a monophyletic clade composed of two subclades, delineating further geographic structure and containing samples from Site 1 (blue), Site 2 (green), and Site 3 (gold). Additional orthohantavirus reference sequences were obtained through NCBI. The scale bar represents the number of nucleotide substitutions per site. US United States, MX Mexico, TX Texas, SLP San Luis Potosí, NL Nuevo León, EM State of Mexico, AZ Arizona, NM New Mexico.
Because there were no previously published sequences for the L segment of “LSCV”, we placed our sequences in a phylogenetic framework by alignment. Similar to the S and M segment sequences, the L segment sequences from New Mexico clustered together and the MSB:Mamm:332771 sequence diverged (Fig. 5).

A maximum-likelihood tree was generated using a General Time Reversible model based on nucleotides of the L segment (RNA-dependent RNA polymerase) of multiple reported sequences of orthohantavirusess. There are 1,000 bootstraps supported. MSB:Mamm:332771 (red) indicates reference genome generated. Samples from New Mexico formed a monophyletic clade composed of two subclades, delineating further geographic structure and containing samples from Site 1 (blue), Site 2 (green), and Site 3 (gold). Partial fragments were generated for MSB:Mamm:264927 so both were aligned and mapped to reference sequences and specimens. Additional orthohantavirus reference sequences were obtained through NCBI. The scale bar represents the number of nucleotide substitutions per site. US United States, MX Mexico, TX Texas, SLP San Luis Potosí, NL Nuevo León, EM State of Mexico, AZ Arizona, NM New Mexico.
A comparison of the total coding “LSCV” sequence spanning all three segments against other known orthohantaviruses revealed that the closest relative is MTNV. Using MSB:Mamm:332771, since it is the only “LSCV” sequence with complete coding regions, we analyzed the percent identity between virus genome sequences. Compared to MTNV sequences, we found 29.9, 22.1, and 6.5% nucleotide divergence and 6.5, 11.8, and 9.6% deduced amino-acid sequence divergence for the S, M, and L segment sequences, respectively (Supplemental Fig. 3).
Finally, we analyzed the deduced protein sequences against other known reference sequences. As expected, the “LSCV” sequence from MSB:Mamm:332771 grouped with other orthohantaviruses from the Americas and most closely with MTNV (Supplemental Fig. 4). According to the updated International Committee on Taxonomy of Viruses (ICTV) Hantaviridae Study Group guidelines, orthohantavirus species can only be established (or maintained) when at least one coding-complete exemplar virus genome (S + M + L segment) sequence is available and if this sequence sufficiently differs from others in DivErsity pArtitioning by hieRarchical Clustering (DEmARC) analysis56 (updated from Laenen, L. et al.57). DEmARC analysis of the now available coding-complete “LSCV” genome sequence identified it as MTNV56. Although “LSCV” was described prior to the description of MTNV, the MTNV coding-complete genome was deposited in 2012, giving MTNV priority34,35,36. Consequently, the terms “Limestone Canyon virus” and “LSCV” should be considered junior synonyms of “Montaño virus” and “MTNV”, respectively, and hence ought to be abandoned.
Discussion
Early studies suggested that orthohantaviruses and their specific rodent hosts co-evolved, with only occasional species-jumping events19,34,58. Instead, numerous recent studies indicate that such events may occur frequently and that rodents of multiple species can become infected by the same virus17,22,23,24,59,60. Indeed, we and others have shown that rodents from multiple species and genera in a single community can be infected with SNV, diminishing the concept of mammalian species being a barrier for orthohantavirus infection of multiple host reservoirs20,21.
For this study, we determined the coding-complete genome sequence of “LSCV” and found a novel lineage thereof in New Mexico brush deermouse (P. boylii) populations. Using this sequence, we demonstrated “LSCV” to be synonymous with MTNV, which was previously found in deermice of multiple species, such as Aztec and Orizaba deermice in Mexico35,36. Because “LSCV” was previously shown to infect deermice of multiple species, MTNV can now be considered rather promiscuous and geographically broadly distributed53,54. The pathogenic potential of MTNV is unknown and requires investigation.
In New Mexico, the distributions of deermice of multiple species overlap, suggesting that there is high potential for multiple orthohantaviruses to co-occur in the same area and even in the same individual rodent59,61. Understanding geographic variation in hosts and associated orthohantaviruses provides a framework for interpreting evolutionary and ecological processes underlying these pathogens17. Additional efforts to survey brush deermouse populations as well as deermice in general will be necessary to establish the boundaries and distribution of populations to help assess the potential for intra- and inter-species genomic segment reassortment and hence the possibility for novel orthohantavirus emergence.
Methods
Ethics statement
All field procedures were performed following the animal care and use guidelines of the American Society of Mammalogists37. The protocol was approved by the UNM Institutional Animal Care and Use Committee, and specimens were collected under a New Mexico Department of Game and Fish permit to J.A.C. (authorization number 3300). Holistic museum specimens were prepared according to the best practices for emerging pathogen research and databased in a relational collection management system (https://arctosdb.org) to facilitate the linkage of host specimen data and derived pathogen data, which include the exact latitude and longitude for each trap location38,39.
Trapping and sample collection
In late September 2019, 80 Sherman traps (38 × 3.59 × 239 cm; H.B Sherman Co., Tallahassee, Florida, USA) were placed near the upper Red Canyon campground for one night. Traps were baited with a peanut-butter-and-oat mixture, set out in the late evening, and collected early the next morning. Nine rodents were captured as follows: five western deermice (P. sonoriensis, 56%), three brush deermice (P. boylii, 33%), and one white-throated woodrat (Neotominae: Neotoma albigula (Hartley, 1894, 11%); overall trapping success was 11.3%. Collected tissues were snap-frozen on dry ice and included brown fat, spleen, heart, lungs, kidneys, liver, colon (with feces if present), urinary bladder (with urine if present), and serum from whole blood collected by cardiac puncture. All samples were stored at −80 °C until processing.
In 2006, samples were similarly collected in Granite Gap and multiple sites in the Big Burro Mountains in Hidalgo and Grant Counties, New Mexico, placed in liquid nitrogen in the field, and later stored at −80 °C. Tissues (liver, spleen, heart/kidney, and lung) were obtained from museum specimens for confirmation of animal identification and detection of viruses. Holistic voucher specimens were prepared and are archived in the UNM MSB DGR (Supplemental Table 3).
Lung tissue from samples collected in 2006 were retrieved from the MSB DGR biorepository for MSB:Mamm:264887, MSB:Mamm:264891, MSB:Mamm:264893, MSB:Mamm:264923, MSB:Mamm:264924, MSB:Mamm:264927, MSB:Mamm:264934, and MSB:Mamm:264937.
Rodent identification
Standard measurements (total length, tail length, hind foot length [with claw], ear length [from notch], weight, reproductive data [sex, reproductive status, and testes for males, and, if pregnant, embryo crown–rump measurements]) and age were recorded. Species identifications were conducted through a combination of measurement data and morphological characters and confirmed through mitochondrial cytochrome b (CYB) gene sequence analysis. CYB was amplified using 15334L (5’-CTTCATTTTTGGTTTACAAGAC-3’) and L14724 (5’-TGATATGAAAAACCATCGTTG-3’)40. The PCR products were purified using the QIAquick purification PCR Kit (catalog number 28104; Qiagen, Germantown, Maryland, USA) and sent to Sequetech (Mountain View, California, USA) with the 15334L primer for sequencing. CYB gene sequences of the mitochondrial DNA were used to verify the species assignments of the mice captured in 2006. Approximately 10 mg of liver tissue was used to attain DNA via salt extraction41. PCR was performed using primers L14724 and H1591542. Cleaned PCR products were sequenced using BigDye Terminator Cycle Sequencing Ready Reaction mix v1.1 (catalog number 4337449, Applied Biosystems, Waltham, Massachusetts, USA) and the forward primer L14724. Sequence reactions were run on an ABI 3100 automated DNA sequencer in the Molecular Biology Facility in the UNM Biology Department. Cleaned sequences from these mice were analyzed by comparing them to GenBank sequences reported by Tiemann-Boege et al.43 in a Neighbor Joining analysis to confirm the identity of each mouse.
Serology
Serology was performed on the 2006 samples using blood collected by cardiac puncture. The presence of IgG antibodies to SNV nucleoprotein (N) protein (SNV N) and RIOMV N was determined using a strip immunoblot assay (SIA) according to the protocol previously described in Yee et al.44. Briefly, each SIA strip was prepared using a model SB 10 mini slot blot apparatus and had an orientation band of Coomassie blue dye and control bands of 3+ IgG intensity, SNV N antigen, RIOMV N antigen, and a 1+ IgG intensity. Components were vacuum-blotted onto nitrocellulose membrane, allowed to dry, and cut into 2-mm strips. Blood samples were pre-blocked for 30 min in a milk buffer before adding the SIA strips and were incubated overnight on a rocker. Strips were washed three times before adding a goat anti-mouse IgG (H + L) alkaline phosphatase (AP) conjugated secondary antibody (KPL catalog number 475–1806) at a 1:1,000 dilution in phosphate milk buffer and allowing them to incubate with rocking at room temperature for 1 h. Then, strips were washed three times before adding the standard AP developing solution for 20 min to visualize bands. Strips were washed a final three times in ddH2O to stop the reaction. Bands were evaluated while wet and assigned scores using an intensity scale of 0–4.
RNA extraction
RNA extraction for MSB:Mamm:332771, MSB:Mamm:264887, MSB:Mamm:264891, MSB:Mamm:264893, MSB:Mamm:264923, MSB:Mamm:264924, MSB:Mamm:264927, MSB:Mamm:264934, and MSB:Mamm:264937 was performed using the QIAmp Viral RNA Mini Kit (catalog number 52906, Qiagen) according to the manufacturer’s instructions with slight modifications. A total of 40 mg of frozen lung tissue was homogenized using a BeadBug 6 Microtube Homogenizer (Benchmark Scientific, Sayreville, New Jersey, USA) in a bead beater tube preloaded with 1.0 g of 1.0-mm-diameter zirconia beads (catalog number 1107911zx; BioSpec, Bartlesville, Oklahoma, USA), 1.0 g of 2.0-mm-diameter zirconia beads (catalog number 11079124zx; BioSpec), and 600 mL of AVL buffer. The tissue was beaten at 4,350 rpm for 30 s for one cycle. Homogenates were centrifuged, placed in a new 1.5-mL microcentrifuge tube, and re-centrifuged to remove any excess debris. RNA carrier was added to the clear lysate, and RNA isolation proceeded per the manufacturer’s instructions. RNA was extracted from lung tissue samples collected in 2006 using the standard protocols for the RNeasy kit (catalog number 74106; Qiagen).
Primer design
PanHS8 was used to detect and provide partial sequence for the S segment of “LSCV” for MSB:Mamm:33277130.
Samples from 2006 were initially unsuccessfully tested using previously published primers34,45. Subsequently, primers were designed by submitting “LSCV” sequences to Primer3 (https://primer3.ut.ee/) for analyses46. Multiple primers were designed for both the S and M segments, but only two worked for the S segment (LSCS 114–5’-AGTGGACCCGGATGATGTTA-3’ and LSCS 1117−5’-TACGTCGGAGGTAGGATTGG-3’) and three for the M segment (LSCM 2077−5’-ATCCTTGGTCATTGGATGA-3’, LSCM 303−5’-GAATGGCCTCCCTTTCCTAC-3’, and LSCM 3312−5’-TGTGAACGAATGGGACAGAA-3’). Cleaned PCR products were sequenced with the amplification primers using the ABI PRISM BigDye Terminator Cycle Sequencing Ready Reaction (Applied Biosystems). Sequences were determined by running samples on an ABI 3100 automated DNA Sequencer (Applied Biosystems).
RT-qPCR and nested PCR
RT-qPCR and nested PCR for MSB:Mamm:332771 were performed as previously described by Goodfellow, S. M. et al. and Klempa, B. et al., respectively30,47.
For MSB:Mamm:264887, MSB:Mamm:264891, MSB:Mamm:264893, MSB:Mamm:264923, MSB:Mamm:264924, MSB:Mamm:264927, MSB:Mamm:264934, and MSB:Mamm:264937, the presence of RNA was confirmed using absorbance spectrometry. RNA was converted into a cDNA library using the Ominscript Reverse Transcription kit (catalog number 205113; Qiagen). A poly(T) primer was used to construct cDNA. An attempt to amplify the M segment was only performed on the sample from the single mouse in which the S segment was amplified.
WGS and de novo assembly
An Illumina sequencing library from MSB:Mamm:332771 RNA from lung tissue was created using the KAPA RNA HyperPrep Kit with RiboErase (HMR) following manufacturer’s recommended protocol (catalog number 8098131702;Roche, Indianapolis, Indiana, USA). The library was sequenced by TGen (https://tgen.org ;Phoenix, Arizona, USA) on a NovaSeq 6000 (Illumina ;San Diego, California, USA). Pair-end reads (2×150-nt) were generated per sample and transferred to personal database followed by trimming of adapters using TrimGalore v0.6.1 (https://www.bioinformatics.babraham.ac.uk/projects/trim_galore/). Running Kraken2 database, trimmed reads were visualized using KronaTools to generate Krona plots (Supplemental Fig. 1)40,48. After identification, all bunyaviral reads including sub-taxa were extracted. SPAdes Genome Assembler, specifically rnaviralSPAdes, was then run on extracted reads, generating 18 nodes that were put into BLAST to check for orthohantavirus hits49. Eight of the 18 nodes were positive and were aligned for each segment accordingly using CLUSTAL Omega. Gaps for M segment sequences were filled in by Sanger sequencing using primers generated from “LSCV” fragment (#AF307323) in NCBI GenBank.
Phylogenetic analysis
Samples from both studies were aligned with CLUSTAL Omega (https://www.ebi.ac.uk/Tools/msa/clustalo/) and Jalview (https://www.jalview.org/). Molecular Evolutionary Genetics Analysis (MEGA-X - https://www.megasoftware.net/) was used to construct a maximum-likelihood tree with 1,000 bootstraps in a General Time Reversible model based on nucleotides shown to provide a uniform substitution matrix. Phylogenetic trees were generated using Interactive Tree of Life (iTOL - https://itol.embl.de/). CLUSTAL Omega was also used to produce percent identity matrices. Sequences used in the analysis are listed in Supplemental Table 4. ExPASy was used to convert nucleotides into amino acids to view variants.
Data availability
Sequences were deposited in GenBank.
MSB:Mamm:264887 (OR552617–619), MSB:Mamm:264891 (OR552620–622), MSB:Mamm:264893 (OR552623–625), MSB:Mamm:264923 (OR552604–606), MSB:Mamm:264924 (OR552611–613), MSB:Mamm:264927 (OR552607–610), MSB:Mamm:264934 (OR552601–603), MSB:Mamm:264937 (OR552614–616), and MSB:Mamm:332771 (OR148902–OR148904). All museum metadata is available via Arctos (https://arctosdb.org).
References
Kuhn, J. H. & Schmaljohn, C. S. A brief history of bunyaviral family Hantaviridae. Diseases 11, 38 (2023).
Lee, H. W., Lee, P. W., Baek, L. J., Song, C. K. & Seong, I. W. Intraspecific transmission of Hantaan virus, etiologic agent of Korean hemorrhagic fever, in the rodent Apodemus agrarius. Am. J. Trop. Med. Hyg. 30, 1106–1112 (1981).
Lee, H. W., Lee, P. W. & Johnson, K. M. Isolation of the etiologic agent of Korean hemorrhagic fever. J. Infect. Dis. 137, 298–308 (1978).
Kuhn, J. H. & Crozier, I. in Harrison’s Principles of Internal Medicine 2 (eds J. Loscalzo et al.) Ch. 209, 1624-1645 (McGraw-Hill Education, 2022).
World Health Organization. International Classification of Diseases 11th Revision (ICD-11). https://icd.who.int/browse11/l-m/en. (2023).
Lee, P.-W. et al. New haemorrhagic fever with renal syndrome-related virus in indigenous wild rodents in United States. Lancet 320, 1405 (1982).
Greenbaum, I. F., Honeycutt, R. L. & Chirhart, S. E. in From Field to Laboratory: A Memorial Volume in Honor of Robert J. Baker. Special Publications, Museum of Texas Tech University, 71 (eds R. D. Bradley, H. H. Genoways, D. J. Schmidley, & L. C. Bradley) 559-575 (2019).
Duchin, J. S. et al. Hantavirus pulmonary syndrome: a clinical description of 17 patients with a newly recognized disease. N. Engl. J. Med. 330, 949–955 (1994).
Nichol, S. T. et al. Genetic identification of a hantavirus associated with an outbreak of acute respiratory illness. Science 262, 914–917 (1993).
López, N., Padula, P., Rossi, C., Lázaro, M. E. & Franze-Fernández, M. T. Genetic identification of a new hantavirus causing severe pulmonary syndrome in Argentina. Virology 220, 223–226 (1996).
Martínez, V. P. et al. “Super-spreaders” and person-to-person transmission of Andes virus in Argentina. N. Engl. J. Med. 383, 2230–2241 (2020).
Kuhn, J. H. et al. Annual (2023) taxonomic update of RNA-directed RNA polymerase-encoding negative-sense RNA viruses (realm Riboviria: kingdom Orthornavirae: phylum Negarnaviricota). J. Gen. Virol. 104, 001864 (2023).
Kuhn, J. H. et al. Pending reorganization of Hantaviridae to include only completely sequenced viruses: a call to action. Viruses 15, 660 (2023).
Guo, W.-P. et al. Phylogeny and origins of hantaviruses harbored by bats, insectivores, and rodents. PLoS Pathog. 9, e1003159 (2013).
Haydon, D. T., Cleaveland, S., Taylor, L. H. & Laurenson, M. K. Identifying reservoirs of infection: a conceptual and practical challenge. Emerg. Infect. Dis. 8, 1468–1473 (2002).
Hughes, A. L. & Friedman, R. Evolutionary diversification of protein-coding genes of hantaviruses. Mol. Biol. Evol. 17, 1558–1568 (2000).
Morzunov, S. P. et al. Genetic analysis of the diversity and origin of hantaviruses in Peromyscus leucopus mice in North America. J. Virol. 72, 57–64 (1998).
Plyusnin, A. & Morzunov, S. P. Virus evolution and genetic diversity of hantaviruses and their rodent hosts. Curr. Top. Microbiol. Immunol. 256, 47–75 (2001).
Ramsden, C., Holmes, E. C. & Charleston, M. A. Hantavirus evolution in relation to its rodent and insectivore hosts: no evidence for codivergence. Mol. Biol. Evol. 26, 143–153 (2009).
Childs, J. E. et al. Serologic and genetic identification of Peromyscus maniculatus as the primary rodent reservoir for a new hantavirus in the southwestern United States. J. Infect. Dis. 169, 1271–1280 (1994).
Goodfellow, S. M. et al. Tracing transmission of Sin Nombre virus and discovery of infection in multiple rodent species. J. Virol. 95, e0153421 (2021).
Burns, J. E. et al. Novel focus of Sin Nombre virus in Peromyscus eremicus mice, Death Valley National Park, California, USA. Emerg. Infect. Dis. 24, 1112–1115 (2018).
Jay, M. et al. Seroepidemiologic studies of hantavirus infection among wild rodents in California. Emerg. Infect. Dis. 3, 183–190 (1997).
Quizon, K. et al. Experimental infection of Peromyscus species rodents with Sin Nombre virus. Emerg. Infect. Dis. 28, 1882–1885 (2022).
Doty, J. B., Dragoo, J. W., Black, W. C. IV, Beaty, B. J. & Calisher, C. H. Peromyscus maniculatus in eastern Colorado: a subspecies with lower prevalence of Sin Nombre virus infection. J. Mammal 93, 183–197 (2012).
Klempa, B. Reassortment events in the evolution of hantaviruses. Virus Genes 54, 638–646 (2018).
Bedford, N. L. & Hoekstra, H. E. The natural history of model organisms: Peromyscus mice as a model for studying natural variation. Elife 4, https://doi.org/10.7554/eLife.06813 (2015).
Malaney, J. L., Dunnum, J. L. & Cook, J. A. Cenozoic vertebrate paleontology: tribute to Arthur H. Harris. N. M. Mus. Nat. Hist. Sci. Bull. 88, 361–369 (2022).
Yates, T. L. et al. The Ecology and Evolutionary History of an Emergent Disease: Hantavirus Pulmonary Syndrome: Evidence from two El Niño episodes in the American Southwest suggests that El Niño–driven precipitation, the initial catalyst of a trophic cascade that results in a delayed density-dependent rodent response, is sufficient to predict heightened risk for human contraction of hantavirus pulmonary syndrome. BioScience 52, 989–998 (2002).
Goodfellow, S. M. et al. Use of a novel detection tool to survey orthohantaviruses in wild-caught rodent populations. Viruses 14, 682 (2022).
Park, K. et al. Multiplex PCR-based nanopore sequencing and epidemiological surveillance of Hantaan orthohantavirus in Apodemus agrarius, Republic of Korea. Viruses 13, 847 (2021).
Taylor, M. K. et al. Amplicon-based, next-generation sequencing approaches to characterize single nucleotide polymorphisms of Orthohantavirus Species. Front. Cell Infect. Microbiol 10, 565591 (2020).
Simmonds, P. et al. Consensus statement: virus taxonomy in the age of metagenomics. Nat. Rev. Microbiol. 15, 161–168 (2017).
Sanchez, A. J., Abbott, K. D. & Nichol, S. T. Genetic identification and characterization of Limestone Canyon virus, a unique Peromyscus-borne hantavirus. Virology 286, 345–353 (2001).
Kariwa, H. et al. Genetic diversity of hantaviruses in Mexico: identification of three novel hantaviruses from Neotominae rodents. Virus Res. 163, 486–494 (2012).
Saasa, N. et al. Ecology of hantaviruses in Mexico: genetic identification of rodent host species and spillover infection. Virus Res. 168, 88–96 (2012).
Sikes, R. S. & Gannon, W. L., Animal Care and Use Committee of the American Society of Mammalogists. Guidelines of the American Society of Mammalogists for the use of wild mammals in research. J. Mammal 92, 235–253 (2011).
Dunnum, J. L. et al. Biospecimen repositories and integrated databases as critical infrastructure for pathogen discovery and pathobiology research. PLoS Negl. Trop. Dis. 11, e0005133 (2017).
Galbreath, K. E. et al. Building an integrated infrastructure for exploring biodiversity: field collections and archives of mammals and parasites. J. Mammal 100, 382–393 (2019).
Ondov, B. D., Bergman, N. H. & Phillippy, A. M. Interactive metagenomic visualization in a Web browser. BMC Bioinformatics 12, 385 (2011).
Aljanabi, S. M. & Martinez, I. Universal and rapid salt-extraction of high quality genomic DNA for PCR-based techniques. Nucleic Acids Res. 25, 4692–4693 (1997).
Irwin, D. M., Kocher, T. D. & Wilson, A. C. Evolution of the cytochrome b gene of mammals. J. Mol. Evol. 32, 128–144 (1991).
Tiemann-Boege, I., Kilpatrick, C. W., Schmidly, D. J. & Bradley, R. D. Molecular phylogenetics of the Peromyscus boylii species group (Rodentia: Muridae) based on mitochondrial cytochrome b sequences. Mol. Phylogenet. Evol. 16, 366–378 (2000).
Yee, J. et al. Rapid and simple method for screening wild rodents for antibodies to Sin Nombre hantavirus. J. Wildl. Dis. 39, 271–277 (2003).
Johnson, A. M. et al. Laguna Negra virus associated with HPS in western Paraguay and Bolivia. Virology 238, 115–127 (1997).
Rozen, S. & Skaletsky, H. Primer3 on the WWW for general users and for biologist programmers. Methods Mol. Biol. 132, 365–386 (2000).
Klempa, B. et al. Hantavirus in African wood mouse, Guinea. Emerg. Infect. Dis. 12, 838–840 (2006).
Wood, D. E., Lu, J. & Langmead, B. Improved metagenomic analysis with Kraken 2. Genome Biol. 20, 257 (2019).
Prjibelski, A., Antipov, D., Meleshko, D., Lapidus, A. & Korobeynikov, A. Using SPAdes De Novo Assembler. Curr. Protoc. Bioinformatics 70, e102 (2020).
No, J. S. et al. Comparison of targeted next-generation sequencing for whole-genome sequencing of Hantaan orthohantavirus in Apodemus agrarius lung tissues. Sci. Rep. 9, 16631 (2019).
Victoria, J. G., Kapoor, A., Dupuis, K., Schnurr, D. P. & Delwart, E. L. Rapid identification of known and new RNA viruses from animal tissues. PLoS Pathog. 4, e1000163 (2008).
Radford, A. D. et al. Application of next-generation sequencing technologies in virology. J. Gen. Virol. 93, 1853–1868 (2012).
Milazzo, M. L., Cajimat, M. N. B., Richter, M. H., Bradley, R. D. & Fulhorst, C. F. Muleshoe virus and other hantaviruses associated with neotomine or sigmodontine rodents in Texas. Vector Borne Zoonotic Dis 17, 720–729 (2017).
Milazzo, M. L. et al. Geographic distribution of hantaviruses associated with neotomine and sigmodontine rodents, Mexico. Emerg. Infect. Dis. 18, 571–576 (2012).
Botten, J. et al. Persistent Sin Nombre virus infection in the deer mouse (Peromyscus maniculatus) model: sites of replication and strand-specific expression. J. Virol. 77, 1540–1550 (2003).
Kuhn, J. H. et al. Reevaluate and reorganize family Hantaviridae (order Bunyavirales). International Committee on Taxonomy of Viruses (ICTV) TaxoProp 2023.035M. https://ictv.global/files/proposals/pending?fid=13580#block-teamplus-page-title. (2023).
Laenen, L. et al. Hantaviridae: current classification and future perspectives. Viruses 11, 788 (2019).
Monroe, M. C. et al. Genetic diversity and distribution of Peromyscus-borne hantaviruses in North America. Emerg. Infect. Dis. 5, 75–86 (1999).
Dragoo, J. W. et al. Phylogeography of the deer mouse (Peromyscus maniculatus) provides a predictive framework for research on hantaviruses. J. Gen. Virol. 87, 1997–2003 (2006).
Song, J.-W., Baek, L. J., Nagle, J. W., Schlitter, D. & Yanagihara, R. Genetic and phylogenetic analyses of hantaviral sequences amplified from archival tissues of deer mice (Peromyscus maniculatus nubiterrae) captured in the eastern United States. Arch. Virol. 141, 959–967 (1996).
Findley, J. S., Harris, A. H., Wilson, D. E. & Jones, C. Mammals of New Mexico. (University of New Mexico Press, 1975).
Acknowledgements
S.M.G. was supported by University of New Mexico (UNM) HSC Infectious Disease and Inflammation Program National Institutes of Health (NIH) grant T32AI007. This work was supported in part by a UNM School of Medicine Research Allocation Committee grant (S.B.B.). We thank the UNM Center for Advanced Research Computing, supported in part by the National Science Foundation, for providing the research computing resources used in this work. Funding for this project was provided by the Defense Advanced Research Projects Agency (No. DARPA-N00014-03-1-0900) to J.W.D (and others), K.E.C. was supported by the Student Research Associate Program through the Defense Threat Reduction Agency. A grant (P20 RR18754) from the National Center for Research Resources (NCRR), a component of the National Institutes of Health (NIH), provided additional funding. This work was also supported in part through a Laulima Government Solutions, LLC, prime contract with the U.S. National Institute of Allergy and Infectious Diseases (Contract No. HHSN272201800013C). J.H.K. performed this work as an employee of Tunnell Government Services (TGS), a subcontractor of Laulima Government Solutions, LLC, under Contract No. HHSN272201800013C. The views and conclusions contained in this document are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the U.S. Department of Health and Human Services or of the institutions and companies affiliated with the authors, nor does mention of trade names, commercial products, or organizations imply endorsement by the U.S. Government. We thank Mariel Campbell for assistance in tissue loans through the Museum of Southwestern Biology, Division of Genomic Resources. Kristin Moore assisted with field work during the 2006 study. The 2006 DNA extractions and PCRs were conducted in J.A.C.’s laboratory and sequencing of rodent DNA and viruses was performed in the Molecular Biology Facility, Biology Department. We also thank Anya Crane (Integrated Research Facility at Fort Detrick, National Institute of Allergy and Infectious Diseases, National Institutes of Health) for critically editing the manuscript.
Author information
Authors and Affiliations
Contributions
S.M.G., V.J.M., R.A.N., K.E.C., D.B.D., D.L.D. and K.C.S. were involved in viral sequencing preparation and analyses. S.M.G., R.A.N., K.E.C., J.W.D., J.A.C., J.L.D. and D.H.-G. performed the animal collection, tissue processing, and permitting processes. J.A.C. and S.B.B. were supported by NSF 2155222. S.M.G., K.E.C., J.W.D. and S.B.B. designed the study and S.M.G., J.H.K. and S.B.B. analyzed results and wrote the paper. All authors read, reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Goodfellow, S.M., Nofchissey, R.A., Morley, V.J. et al. Genome sequencing identifies “Limestone Canyon virus” as Montaño virus (Hantaviridae: Orthohantavirus montanoense) circulating in brush deermice in New Mexico. npj Viruses 2, 11 (2024). https://doi.org/10.1038/s44298-024-00016-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s44298-024-00016-6
