
Abstract
Technological advances in omics evaluation, bioinformatics, and artificial intelligence have made us rethink ways to improve patient outcomes. Collective quantification and characterization of biological data including genomics, epigenomics, metabolomics, and proteomics is now feasible at low cost with rapid turnover. Significant advances in the integration methods of these multiomics data sets by machine learning promise us a holistic view of disease pathogenesis and yield biomarkers for disease diagnosis and prognosis. Using machine learning tools and algorithms, it is possible to integrate multiomics data with clinical information to develop predictive models that identify risk before the condition is clinically apparent, thus facilitating early interventions to improve the health trajectories of the patients. In this review, we intend to update the readers on the recent developments related to the use of artificial intelligence in integrating multiomic and clinical data sets in the field of perinatology, focusing on neonatal intensive care and the opportunities for precision medicine. We intend to briefly discuss the potential negative societal and ethical consequences of using artificial intelligence in healthcare. We are poised for a new era in medicine where computational analysis of biological and clinical data sets will make precision medicine a reality.
Impact
-
Biotechnological advances have made multiomic evaluations feasible and integration of multiomics data may provide a holistic view of disease pathophysiology.
-
Artificial Intelligence and machine learning tools are being increasingly used in healthcare for diagnosis, prognostication, and outcome predictions.
-
Leveraging artificial intelligence and machine learning tools for integration of multiomics and clinical data will pave the way for precision medicine in perinatology.
Similar content being viewed by others


Introduction
Technological advances have changed the way we live and work. Today, a device worn around our wrists carries more computing capability than devices that required large, cooled rooms in the early 1950s. The emergence of self-driving vehicles, facial and voice recognition, and the integration of human cognition with the rapid processing of artificial intelligence (AI) are all examples of these advances. Newly developed AI strategies in radiology, retinal scanning, diagnosis of skin lesions, and interpretation of normal or abnormal cardiac rhythmicity have improved diagnostic capabilities that exceed those of even the most skilled clinicians.1,2,3
Concomitant to and aided by the development of AI is the emergence of the various “omic” disciplines. The sequencing of the first human genome during the 1990s took nearly a decade to accomplish and cost nearly a billion dollars. This task can now be done in less than a day for slightly over 100 US dollars. As described by Euan Angus Ashely, in his book “the Genome Odyssey,” the relative cost of having one’s genome sequenced compared to a couple of decades ago can be equated to being able to buy a new Ferrari automobile for a few coins.4 Other omics and non-omics data can now be integrated with genomic data using various bioinformatic platforms melding nature (the genome) with nurture (the effects of the environment) as a means to explain the mechanisms of normal physiology and what goes awry during disease.5
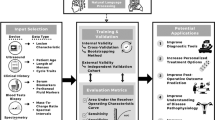
History has helped us discern three eras of medicine (Fig. 1). We have gone through an era of “intuition-based medicine,” which relied largely on what is known about signs and symptoms, pathophysiology of disease, the experience of the clinician, and their diagnostic and therapeutic skills. Currently, we strive to make judgments using “evidence-based medicine” where diagnostics and therapeutics are based on evidence from clinical studies and Gaussian statistics. More recently, there has been a drive to refocus our efforts toward prevention rather than treatment of illnesses and health disorders. Prevention requires early detection of features both clinical and laboratory that can be used to minimize adverse consequences associated with a developing illness. An example related to neonatal nutrition would be a paradigm shift from following growth curves and acting when growth failure is detected (delayed intervention) to the identification of biomarkers that could predict growth failure even before it occurs. Biomarkers could inform individualized pre-emptive strategies that prevent even the beginnings of growth faltering seen on growth curves.6

Evolution of medicine in the past, present, and future. In the past, medicine was practiced by evaluation of signs and symptoms and based solely on the knowledge of the individual physician and was intuition medicine. Currently, medicine is based on scientific research including clinical trials and is evidence-based medicine. In the future, medicine will be practiced by algorithms based on the patient’s phenotype, genome, epigenome, or other omics data that will individualize treatment and that which constitute precision medicine.
The value of AI and multiomics for studying various aspects of normal and pathologic pregnancy and the newborn period is being increasingly recognized.7,8,9 In this review, we intend to discuss recent research integrating multiomics using machine learning (ML) tools in the field of Perinatology. Not only will we discuss the technical advances but will discuss ethical and societal considerations that should be addressed.
Description of multiomics
The term “omics” describes the collective characterization and quantification of large data sets including the genome, transcriptome, proteome, microbiome and epigenome that influence the structure, function, and dynamics of a biological process.5,10 Recent biotechnological advances have enabled researchers to generate systems-level profiling of patients at multiple omics levels with increasing dimensionality (Fig. 2). Table 1 shows some of the types of “omics” that are currently being explored in clinical and basic science research.

Search words used were: “multiomics,” “multiomics AND integration,” “multiomics AND machine learning” and “multiomics AND deep learning”.
Many of these “omics” have been studied individually (single omics) and correlated with phenotypic data under different stressors, which have yielded some interesting associations, but do not provide enough mechanistic information to support causal relationships. An interesting corollary is found in the Indian parable of the “six blind men of Hindustan”. Each of these six men was asked to feel a portion of an elephant. One felt the side and was convinced this was a wall. Another felt the tusk and was convinced this was a spear. Another felt the tail and stated this was a rope and so on. They argued about what they felt, and their conclusions differed. So, in addition to being blind, they were also intellectually short sighted in that they did not open their minds to the others’ perspectives and thus were not able to identify the whole animal, the elephant. Similarly, if we attempt to associate individual omics only to a particular disease or phenotype, we will fail to identify the holistic mechanistic pathway that leads to differences in the phenotype. Integration of multiple omics using “state-of-the-art” bioinformatic techniques can yield networks that provide mechanistic clues and answers that relate to causality (Fig. 3).

Multiple omics data types are depicted in the different layers. Circles in each colored panel represent the entire pool of molecules from which the omics data are collected. Genetic regulation and environment impact the molecules in each layer except the genome layer. The thin black arrows represent potential interactions or correlations detected between molecules in different layers, for example, the red transcript can be correlated with multiple proteins. Thick colored arrows near the top of the panel point to different potential starting points for consolidating multiple omics data to understand biological systems and pathogenesis of disease. The genome first approach (thick gray arrow) implies that one starts from the associated genetic locus, while the phenotype first approach may start from any other omics layer. The environment first approach (not shown) examines environmental perturbations.
Description of machine learning
ML has been described as the ability of machines to “think” and includes any computer program that improves its performance at some task through experience.11 The different terminologies related to ML are tabulated in Table 2. ML models can be categorized as supervised and unsupervised. Supervised learning methods use label information from samples or clinical outcome data for model training. Unsupervised learning is used when there are no labeled data or outcomes and identifies patterns (or clusters) in the data by principal co-ordinate analysis. Supervised and less commonly unsupervised learning have been most commonly applied to multiomics data integration in perinatology.
Clinical research studies often evaluate many ML models and choose the one based on predictive accuracy. Most commonly evaluated ML models are logistic regression, k-nearest neighbors, random forest, gradient boosting machine, (kernel) support vector machine, and artificial neural networks (ANNs or NNs).12,13 ANNs are ML models that conceptually resemble the organization of the brain and neurons. Neural models are able to represent complex, nonlinear functions with reasonable computational costs. More recently, kernelized version of NNs has been developed that restricts the massive expressive power of NNs while still capturing nonlinear relationships, and also controls the smoothness of the resulting predictive models.14
An example of selecting the best possible model is by hyper-parameter optimization.13 Hyper-parameters are additional, model-dependent parameters that are specified before the learning phase, e.g., the value of k in k-nearest neighbor or the number of hidden units in a neural network. Ensuring proper generalization involves finding sub-optimal values of the hyper-parameters. Each model is subjected to the hyper-parameter optimization procedure and the model with the highest area under the receiver-operated characteristic curve (AUROC) is chosen. The model is validated with a separate data set other than the one it is trained on (internal or external data set validation).
AUROC is the most commonly used metric of choice to compare models for predictive accuracy. A receiver-operated characteristic curve (ROC) is a plot of the true positive rate (sensitivity) as a function of the false positive rate (1 – specificity) for different values at each threshold parameter. If a classifier (or test) is perfect, the ROC curve passes through the upper left corner (sensitivity and specificity of 1) and therefore the AUROC measures the overall accuracy of the classifier/test. An AUROC value of 0.5 indicates that the model is equivalent to a coin toss, while a value of 1.0 indicates perfect predictions. The goodness-of-fit of the considered models is assessed by calculating the Brier loss. The lower the Brier loss, the better the goodness-of-fit, with values of 0.25 equivalent to a coin toss and 0 that of a perfect forecast.15
ML approaches like neural networks are a new frontier in clinical decision-making, having recently made dramatic advances in medical image analysis and other fields.16,17,18 Recent evidence suggests that ML approaches may improve clinical outcomes in a variety of diseases including congenital cataracts, metastatic breast cancer, postprandial glucose prediction, and diabetic retinopathy.19,20,21,22,23,24,25
Integration of multiomics with machine learning strategies
As with the six blind men parable, it would have helped had they collaborated and discussed their findings and then developed a conclusion. Multiomic integration approaches that evaluate changes over time are needed, especially in perinatology, which presents critical windows for nutrition, growth, and epigenetic modeling.6
Multiomics data integration approaches may be categorized as early, intermediate and late (Fig. 4).10,26 Early integration or early concatenation although not complicated, may have problems with very few data points but numerous features, often known as the “curse of dimensionality”.27 For example, multiomics data sets may contain more than thousands of features when the genome, transcriptome, and proteome are combined but the number of patient samples may be relatively small (hundreds or less). Another problem that needs to be addressed is heterogeneity; omics data sets can have variable data distribution or data types (e.g., numerical, categorical, continuous, discrete) and differ significantly in the number of features. Dimensionality reduction is the process of reducing the number of variables or features in order to decrease the dimensionality and noise of a data set. Early and intermediate integration processes often require prior dimensionality reduction to be more effective and functional.

Multiomics data integration may be categorized by the timing of integration related to analysis and interpretation as early, intermediate, and late. The features from different data matrices are concatenated early in early integration but challenged by high dimensionality but few number of samples. Intermediate integration strategy involves each omic data set being transformed into a simpler representation by dimensionality reduction and the combined data set is consolidated by machine learning without concatenating features or merging results. Late integration involves the results of each multiomic data set combined terminally after each omics layer is analyzed independently.
The intermediate integration strategy transforms each omics data set independently into a simpler representation, thus overcoming some issues with the early integration strategy. Transformation facilitates analysis by converting the data set to a less dimensional and less noisy one and also decreases heterogeneity between omics data sets such as the data’s type or size differences. The transformed and combined representation can then be analyzed by classical ML models, which include three transformation methods namely kernel-based methods, graph-based methods, and deep learning.28 ML methods used for intermediate integration are either general-purpose methods that couple dimensionality reduction with different downstream algorithms for a variety of tasks or applications or end-to-end models designed for one specific task.10
Late integration combines the results from each omics layer or each omics data set by ML tools (or manually) and the predictions performed terminally.10,28 Since each omics data set is analyzed by omic-specific ML tools, the problems of noise and heterogeneity found in other strategies are not present. However, the downside of the late integration strategy is that it cannot capture inter-omics interactions as the different ML models (for the different omics data sets) do not share complementary information between omics.28 Combining predictions as in the late integration strategy may not fully bring out the details and complexity of multiomics data analysis and interpretation to understand the biological mechanisms of diseases.
Various software for multiomics integrations already exist and innovative methods and procedures are being developed to integrate multiomics data with the clinical phenotype. Using these techniques one can delineate and understand the strength of correlations between the individual’s omics data including the genome, microbiome, metabolome, and epigenome. Multiset sparse partial least squares path modeling (msPLS) for high-dimensional omics data analysis (https://doi.org/10.1186/s12859-019-3286-3)29 is a novel statistical method that models and helps us understand biological pathways and genetic architectures of complex phenotypes. The effect of multiple molecular markers, from multiple omics domains, on the variation of multiple phenotypic variables is simultaneously modeled. The sparsity in the model provides interpretable results from analyses of hundreds of thousands of biomolecular variables. msPLS has been shown to outperform Multi-Omics Factor Analysis30 in terms of variation explained in a chronic lymphocytic leukemia data set. Another method called MOTA (https://doi.org/10.3390/metabo10040144) is a network-based method that uses multiomics data to rank candidate disease biomarkers.31 Thus, researchers can use MOTA to investigate the biological significance of the highly ranked biomarkers.31
Clinical applications
Challenges of pregnancy
Pregnancy-associated pathology may lead to complications such as preterm birth (PTB), preeclampsia, and fetal growth restriction. Prematurity is the leading cause of neonatal morbidity and mortality. Many babies born preterm require prolonged neonatal hospital stays and have complications such as necrotizing enterocolitis (NEC), bronchopulmonary dysplasia (BPD), neurodevelopmental disorders, and growth delays. The application of omics data from high throughput analysis such as with epigenomics data that show modifications of DNA or histone configurations may help us understand the cellular processes of different cell types in the developing fetus and placenta and whether they are functioning properly for a successful pregnancy. Longitudinal multiomic data analysis during the various stages of pregnancy is likely to lead to early diagnosis of risk and novel methods for therapy and prevention. Some examples of the use of multiomics and ML in pregnancy are discussed below.
Multiomics modeling and delineating metabolome adaptations during human pregnancy may provide the framework for future studies.32 Ghaemi et al. performed a multiomics analysis of the immunome, transcriptome, microbiome, proteome, and metabolome from 17 pregnant women (51 samples), delivering at term.32 The investigators used multivariate predictive modeling using the Elastic Net algorithm to measure the ability of each data set to predict gestational age. Multiomics data sets were combined using stacked generalization, which increased the predictive power and revealed novel interactions among multiomic data sets.
A healthy pregnancy is a cumulation of complex interrelated biological adaptations involving placentation, maternal immune responses, and hormonal homeostasis. Understanding these biological adaptations by multiomics integration using state-of-the-art machine-learning methods is imperative to predict short- and long-term health trajectories for a mother and the offspring. These principles are delineated by data-driven modeling of pregnancy-related complications.33 Maric et al. investigated modeling of preeclampsia using longitudinal multiomics data and developed a multiomics model using ML.34 The multiomics model had high accuracy (AUROC of 0.94 [95% confidence intervals (CI) 0.90–0.99]). Ten urine metabolites were found to be major players in this model, which was validated using an independent cohort of 16 women (AUROC of 0.87 [95% CI 0.76–0.99]). The prediction accuracy of the urine metabolome model could be improved with the integration of clinical variables (AUC = 0.90 [95% CI 0.80–0.99]). This multiomics integration study identified several biological pathways associated with preeclampsia.
Integration of multiomics trajectories of the maternal metabolome, proteome, and immunome may be useful to predict labor onset.35 Progression of pregnancy toward birth is associated with major transitions that occur in feto-maternal immune, metabolic, and endocrine systems. In a longitudinal study conducted on 63 women who went into spontaneous labor, serial blood samples were collected during the last 100 days of pregnancy. More than 7000 plasma analytes and peripheral immune cell responses were analyzed using untargeted mass spectrometry, aptamer-based proteomic technology, and single-cell mass cytometry. An integrated multiomic model predicted the time to spontaneous labor [(R = 0.85, 95% CI [0.79–0.89], P = 1.2 × 10−40, N = 53, training set); (R = 0.81, 95% CI [0.61–0.91], P = 3.9 × 10−7, N = 10, independent test set)]. Coordinated alterations in the maternal metabolome, proteome, and immunome marked a molecular shift from pregnancy maintenance to pre-labor biology, 2–4 weeks before delivery. Regulation of inflammatory responses preceded labor that was associated with a surge in steroid hormone metabolites and interleukin-1 receptor type 4.
Multiomics integration and modeling of transcriptomics and proteomics profiling of plasma and urine metabolomics may identify PTB (delivery before 37 weeks gestation).36 Plasma and urine samples were analyzed from 81 pregnant women in 5 biorepository cohorts in low- and middle-income countries. Of the 81 pregnant women, 39 had PTBs (48.1%) and 42 had term pregnancies (51.9%) (mean [SD] age of 24.8 [5.3] years). A cohort-adjusted ML algorithm was applied to each biological data set, and the results were combined into a final integrative model using ML. The integrated model was more accurate, with an AUROC of 0.83 [95% CI, 0.72–0.91] compared with the models derived for each independent omic data set (transcriptomics AUROC, 0.73 [95% CI, 0.61–0.83]; metabolomics AUROC, 0.59 [95% CI, 0.47–0.72]; and proteomics AUROC, 0.75 [95% CI, 0.64–0.85]). Primary features associated with PTB included a serum inflammatory module and a urine metabolomic module associated with glutamine and glutamate metabolism and valine, leucine, and isoleucine biosynthesis pathways. This is an excellent example of the integration of multiomic data sets with ML tools that will lead to predictive tests and intervention candidates for preventing PTB.
The neonatal intensive care unit
There are numerous areas in neonatal intensive care where AI combined with multiomics shows promise and will likely become an important adjunct for disease prediction, diagnostics, and therapeutics. Longitudinal continuous monitoring of heart rate tracings, pulse oximetry, and ventilation patterns generate data that can be interrogated by ML. Several poorly defined “diseases” in neonatal intensive care such as sepsis, NEC, BPD, and various forms of encephalopathy for which use of AI and multiomic-based methods have the potential to markedly alter our current definitions and improve management.
Retinopathy of prematurity
An excellent example of the use of AI is retinopathy of prematurity (ROP), which can now be detected much earlier and more accurately using these methods.37,38,39 As an illustration (Fig. 5), features seen in the retina during development in preterm infants can be utilized using user-defined definitions or machine-learned features to provide an accurate diagnosis of this disease.1

Early efforts to automate the diagnosis of ROP used features such as vessel type, dilation, tortuosity, and location, and a score was developed without a computer algorithm (e.g., ROPtool). Machine learning uses a classifier step that relates the features to the diagnosis. Deep convoluted neural networks (CNN) differ from traditional ML algorithms such as support vector machine by letting the machine learn the features related to the input image that correlates with the diagnosis without human-defined features.
Necrotizing enterocolitis
Defining NEC remains an enigma and 8 different definitions have been proposed,40 but none are considered satisfactory. Definitions attempt to define distinct entities and what we term “NEC” today is not a distinct entity,41 thus is not readily amenable to a definition.
The need to revise the outdated modified Bell staging criteria is crucial in improving NEC management.41,42 Recent data suggests that genetic susceptibility and stool microbiota signatures may help identify preterm infants at increased risk of the disease.43,44 Ongoing studies using single or multiomic approaches may help to characterize biomarkers that could predict different intestinal injuries currently being termed as “NEC”. Intestinal ultrasound may improve diagnostic accuracy for NEC but has been slow in adoption. Patient family perspectives are key in accelerating our efforts to integrate newer diagnostic methods into practice.42 At the very least, we are beginning to recognize that the Bell staging criteria are not optimal and better criteria are needed.40
Several attempts have been made to differentiate what we term classical NEC from some of the “imposters.” For example, NEC can be confused with spontaneous intestinal perforation (SIP) even with the availability of clinical and laboratory information.45,46 Supervised ML was used to evaluate NEC versus SIP, which can be differentiated at laparotomy, but the increasing use of peritoneal drains without direct visualization of the bowel limits the accuracy of the diagnosis. In a recent study that evaluated several clinical and radiographic features in infants who had undergone surgery where necrosis was clearly found versus isolated ileal perforation, ML was able to readily delineate several features that are helpful in differentiating these two outcomes prior to surgery.47
Other studies have evaluated the stool microbiome prior to NEC using ML techniques that suggest the possibility of their use as biomarkers.48 Another study employed clinical and imaging preterm infant data from six neonatal centers using AI approaches to determine their relationship to the development of NEC and found that such an approach may be feasible.49 Now, it is reasonable to infer that a completely new approach to intestinal injuries in the neonatal intestine is in order. Use of multiomic approaches along with AI47 can be used to differentiate the different forms of intestinal injury or dysfunction that are labeled as NEC.50,51 AI strategies may make it possible to redefine the different forms of intestinal injury commonly seen in preterm infants into different clusters that derive from different pathophysiology. By doing this, each one of these clusters can be better evaluated for discrete mechanisms, biomarkers, and preventative strategies.
Precision nutrition as an example of integration of omics and AI
One of the greatest challenges in Neonatology remains how to optimize the timing and composition of nutrition in preterm infants to achieve appropriate growth, while minimizing devastating outcomes such as intestinal injury, LOS, BPD, and ROP. Progress has been made since the era of delayed feeding of high-risk preterm infants. Many guideline-based approaches have been developed that have good evidence-based foundations (as described in the second era of medicine in the Introductory section of this review). Such approaches may be adequate for many of these infants, but a significant percentage require a more personalized (precision) approach based on the individual’s genetic makeup and omics data rather than traditional dogma, anecdotal clinical experience, or even good clinical studies that evaluate populations rather than individuals. In accordance with concerns raised by the National Institute of Health (NIH) Precision Nutrition Initiative, the “one size fits all” approach marginalizes many of these infants and may even lead to harm. For example, not until recently has sex been evaluated as an important variable that relates to nutritional needs. In addition, preterm infants may exhibit weight gains commensurate with standardized growth curves, but still develop adverse outcomes such as NEC, ROP, BPD, and LOS. Some of these outcomes may depend on previous in utero developmental events that are not considered when simply using a postnatal growth curve approach.
The development of precision-based nutritional strategies that leverage newly developed integration of “multiomics,” systems biology, and ML will significantly improve and optimize growth and reduce adverse outcomes in preterm infants. Using multiomics (microbiome, metabolome, and inflammasome) based systems biology network analysis along with AI will then identify biomarkers to guide personalized interventional strategies for high-risk infants in order to mitigate adverse short- and long-term outcomes experienced by these infants. ML Integration of blood parameters, dietary habits, anthropometrics, physical activity, and gut microbiota has shown to predict personalized postprandial glycemic response to real-life meals in adults.21,52 Similar studies promoting precision nutrition in neonates have not been performed.
Precision nutrition explores and incorporates the effects of the complex interplay among genetics, microbiome, antibiotic and probiotic use, metabolism, food environment, and physical activity, as well as economic, social, and other behavioral characteristics.53 The NIH is leading efforts to advance the field of precision nutrition with a plan 2020–2030 with strategic goals to address precision nutrition research.54
Societal and ethical issues related to the use of AI in healthcare
The intent of AI/ML use in healthcare is to improve diagnosis or predict clinical phenotypes that require intervention, which will then translate to better patient outcomes. However, we should also be mindful of the potential adverse consequences of the use of AI and ML in healthcare as they are increasingly explored for patient care. Societal issues relate to fairness, explainability, privacy, ethics, and legislation, which should be sufficiently addressed in new projects.55 Fairness is a central perspective in healthcare and the models developed by AI/ML should be fair to human characteristics including gender, race, and ethnicity. For example, a predictive model that is developed with one gender, race, or ethnic group only is not likely be applicable to the population at large and is bound to fail in the real world. Privacy is another critical issue in healthcare and the anonymity and privacy of the patients should be respected, if the ML modeling is performed using private information of the patients, e.g., identifiers such as medical record numbers, social security numbers, or even the zip code where they live. Explainability and interpretability are important aspects of clinical medicine, e.g., how a certain exposure leads to disease or a drug leads to side effects. However, ML algorithms, especially deep learning models are considered black boxes where the connection between input and output is obscure, and the function is not explainable. This might be all the more important when the model does not work very well, and the issues are not explainable. Ethical research is the cornerstone of medicine and healthcare, and several questions need to be addressed. Will it be possible for AI and ML models to follow or address the basic biomedical ethical principles of respect for autonomy, non-maleficence, beneficence, and justice? Could the use of AI, if the model is poorly developed, cause more harm than good? Could the use of AI in some way by their predictions increase psychological stress in parents, make the patients poor insurance clients if we predict long-term poor outcomes early? Are there ethical concerns, conflicts of interest, individual on the part of the researcher or clinician, hospital or institution – financial or otherwise?56 How are medico-legal risks that arise from use of AI managed?57 We as proponents of the use of AI/ML should make sure that we address the societal and ethical issues adequately to maximize risk-benefit ratios.
Summary and the future
There are tremendous opportunities for enhancing patient outcomes that technological advances have brought forth, integrating multiomics and clinical data sets with modern computing platforms using ML. The advances and capabilities have the potential to bring about paradigm shifts in how we practice medicine in the fields of perinatal and neonatal medicine. Predictive analytics hold promise for the prevention of disease and improved diagnostics and therapeutics. Potential ethical and societal issues due to the use of ML techniques in healthcare need to be addressed with foresight and wise judgment.
Data availability
This is a review and all data discussed are included in the review.
References
Scruggs, B. A., Chan, R. V. P., Kalpathy-Cramer, J., Chiang, M. F. & Campbell, J. P. Artificial intelligence in retinopathy of prematurity diagnosis. Transl. Vis. Sci. Technol. 9, 5 (2020).
Titano, J. J. et al. Automated deep-neural-network surveillance of cranial images for acute neurologic events. Nat. Med. 24, 1337–1341 (2018).
Terranova, N., Venkatakrishnan, K. & Benincosa, L. J. Application of machine learning in translational medicine: current status and future opportunities. AAPS J. 23, 74 (2021).
Ashley, E. A. The Genome Odyssey (Celadon Books, 2021).
López de Maturana, E. et al. Challenges in the integration of omics and non-omics data. Genes (Basel) 10, 238 (2019).
Lugo-Martinez, J. et al. Integrating longitudinal clinical and microbiome data to predict growth faltering in preterm infants. J. Biomed. Inform. 128, 104031 (2022).
Clapp, M. A. & McCoy, T. H. The potential of big data for obstetrics discovery. Curr. Opin. Endocrinol. Diabetes Obes. 28, 553–557 (2021).
Ramakrishnan, R., Rao, S. & He, J. R. Perinatal health predictors using artificial intelligence: a review. Women’s Health (Lond.) 17, 17455065211046132 (2021).
Garcia-Canadilla, P., Sanchez-Martinez, S., Crispi, F. & Bijnens, B. Machine learning in fetal cardiology: what to expect. Fetal Diagn. Ther. 47, 363–372 (2020).
Cai, Z., Poulos, R. C., Liu, J. & Zhong, Q. Machine learning for multi-omics data integration in cancer. iScience 25, 103798 (2022).
Mitchell, T. Machine Learning 1st edn (McGraw-Hill, 1997).
Podda, M. et al. A machine learning approach to estimating preterm infants survival: development of the Preterm Infants Survival Assessment (PISA) predictor. Sci. Rep. 8, 13743 (2018).
Hastie, T., Tibshirani, R. & Friedman, J. H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction 2nd edn (Springer, 2009).
Sahs, J. et al. Shallow univariate ReLu networks as splines: initialization, loss surface, Hessian, and gradient flow dynamics. Front. Artif. Intell. 5, 889981 (2022).
Brier, G. W. Verification of forecasts expressed in terms of probability. Monthly Weather Rev. 78, 1–3 (1950).
Anwar, S. M. et al. Medical image analysis using convolutional neural networks: a review. J. Med. Syst. 42, 226 (2018).
Lundervold, A. S. & Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. f.ür. Medizinische Phys. 29, 102–127 (2019).
Munir, K., Elahi, H., Ayub, A., Frezza, F. & Rizzi, A. Cancer diagnosis using deep learning: a bibliographic review. Cancers (Basel) 11, 1235 (2019).
Long, E. et al. An artificial intelligence platform for the multihospital collaborative management of congenital cataracts. Nat. Biomed. Eng. 1, 0024 (2017).
Sayres, R. et al. Using a deep learning algorithm and integrated gradients explanation to assist grading for diabetic retinopathy. Ophthalmology 126, 552–564 (2019).
Mendes-Soares, H. et al. Model of personalized postprandial glycemic response to food developed for an israeli cohort predicts responses in midwestern American individuals. Am. J. Clin. Nutr. 110, 63–75 (2019).
Wang, D., Khosla, A., Gargeya, R., Irshad, H. & Beck, A H. Deep learning for identifying metastatic breast cancer. arXiv:1606.05718 [q-bio.QM] (2016).
Wang, D. D. & Hu, F. B. Precision nutrition for prevention and management of type 2 diabetes. Lancet Diabetes Endocrinol. 6, 416–426 (2018).
Wang, P. et al. Real-time automatic detection system increases colonoscopic polyp and adenoma detection rates: a prospective randomised controlled study. Gut 68, 1813–1819 (2019).
Wu, L. et al. Randomised controlled trial of wisense, a real-time quality improving system for monitoring blind spots during esophagogastroduodenoscopy. Gut 68, 2161–2169 (2019).
Zitnik, M. et al. Machine learning for integrating data in biology and medicine: principles, practice, and opportunities. Inf. Fusion 50, 71–91 (2019).
Bellman, R. Dynamic programming. Science 153, 34–37 (1966).
Picard, M., Scott-Boyer, M. P., Bodein, A., Périn, O. & Droit, A. Integration strategies of multi-omics data for machine learning analysis. Comput Struct. Biotechnol. J. 19, 3735–3746 (2021).
Csala, A., Zwinderman, A. H. & Hof, M. H. Multiset sparse partial least squares path modeling for high dimensional omics data analysis. BMC Bioinforma. 21, 9 (2020).
Argelaguet, R. et al. Multi-omics factor analysis–a framework for unsupervised integration of multi-omics data sets. Mol. Syst. Biol. 14, e8124 (2018).
Fan, Z., Zhou, Y. & Ressom, H. W. Mota: network-based multi-omic data integration for biomarker discovery. Metabolites 10, 144 (2020).
Ghaemi, M. S. et al. Multiomics modeling of the immunome, transcriptome, microbiome, proteome and metabolome adaptations during human pregnancy. Bioinformatics 35, 95–103 (2019).
Espinosa, C. et al. Data-driven modeling of pregnancy-related complications. Trends Mol. Med. 27, 762–776 (2021).
Maric, I. et al. Multiomics Longitudinal Modeling of Preeclamptic Pregnancies. https://scholarlycommons.pacific.edu/dugoni-facarticles/729 (2021).
Stelzer, I. A. et al. Integrated trajectories of the maternal metabolome, proteome, and immunome predict labor onset. Sci. Transl. Med. 13, eabd9898 (2021).
Jehan, F. et al. Multiomics characterization of preterm birth in low- and middle-income countries. JAMA Netw. Open 3, e2029655 (2020).
Coyner, A. S. et al. Single-examination risk prediction of severe retinopathy of prematurity. Pediatrics 148, e2021051772 (2021).
Tsai, A. S. et al. Assessment and management of retinopathy of prematurity in the era of anti-vascular endothelial growth factor (VEGF). Prog. Retin. Eye Res. 88, 101018 (2022).
Li, J. et al. Evaluation of artificial intelligence-based quantitative analysis to identify clinically significant severe retinopathy of prematurity. Retina 42, 195–203 (2022).
Lueschow, S. R., Boly, T. J., Jasper, E., Patel, R. M. & McElroy, S. J. A critical evaluation of current definitions of necrotizing enterocolitis. Pediatr. Res. 91, 590–597 (2022).
Neu, J., Modi, N. & Caplan, M. Necrotizing enterocolitis comes in different forms: historical perspectives and defining the disease. Semin. Fetal Neonatal Med. 23, 370–373 (2018).
Kim, J. H., Sampath, V. & Canvasser, J. Challenges in diagnosing necrotizing enterocolitis. Pediatr. Res. 88, 16–20 (2020).
Pammi, M. et al. Intestinal dysbiosis in preterm infants preceding necrotizing enterocolitis: a systematic review and meta-analysis. Microbiome 5, 31 (2017).
Talavera, M. M. et al. Single nucleotide polymorphisms in the dual specificity phosphatase genes and risk of necrotizing enterocolitis in premature infant. J. Neonatal-Perinat. Med. 13, 373–380 (2020).
Berrington, J. & Embleton, N. D. Discriminating necrotising enterocolitis and focal intestinal perforation. Arch. Dis. Child Fetal Neonatal. Ed. 107, 336–339 (2022).
Berrington, J. E. & Embleton, N. D. Time of onset of necrotizing enterocolitis and focal perforation in preterm infants: impact on clinical, surgical, and histological features. Front. Pediatr. 9, 724280 (2021).
Lure, A. C. et al. Using machine learning analysis to assist in differentiating between necrotizing enterocolitis and spontaneous intestinal perforation: a novel predictive analytic tool. J. Pediatr. Surg. 56, 1703–1710 (2021).
Hooven, T. A., Lin, A. Y. C. & Salleb-Aouissi A. Multiple instance learning for predicting necrotizing enterocolitis in premature infants using microbiome data. Proc. ACM Conf. Health Inference Learn 2020, 99–109 (2020).
Ji, J. et al. A data-driven algorithm integrating clinical and laboratory features for the diagnosis and prognosis of necrotizing enterocolitis. PLoS One 9, e89860 (2014).
Neu, J. Necrotizing enterocolitis: a multi-omic approach and the role of the microbiome. Dig. Dis. Sci. 65, 789–796 (2020).
Beck, L. C., Granger, C. L., Masi, A. C. & Stewart, C. J. Use of omic technologies in early life gastrointestinal health and disease: from bench to bedside. Expert Rev. Proteom. 18, 247–259 (2021).
Zeevi, D. et al. Personalized nutrition by prediction of glycemic responses. Cell 163, 1079–1094 (2015).
Rodgers, G. P. & Collins, F. S. Precision nutrition-the answer to “what to eat to stay healthy”. JAMA 324, 735–736 (2020).
NIH. US Department of Health & Human Services. 2020-2030 Strategic Plan for NIH Nutrition Research. https://www.niddk.nih.gov/about-niddk/strategic-plans-reports/strategic-plan-nih-nutrition-research (2020).
Vellido, A. Societal issues concerning the application of artificial intelligence in medicine. Kidney Dis. (Basel) 5, 11–17 (2019).
Morley, J. et al. The ethics of AI in health care: a mapping review. Soc. Sci. Med. 260, 113172 (2020).
Oliva, A. et al. Management of medico-legal risks in digital health era: a scoping review. Front. Med. (Lausanne) 8, 821756 (2021).
Hasin, Y., Seldin, M. & Lusis, A. Multi-omics approaches to disease. Genome Biol. 18, 83 (2017).
Funding
This study was funded by the following extramural sources: NIH R03HD098482, R21HD091718, CA125123; NCI P30CA125123; NIH/NCI R01CA220297, R01CA216426; NIEHS P30 ES030285, P42 ES027725, NIMHD P50MD015496; CPRIT RP170005, R35GM138353, Burroughs Wellcome Fund (1019816), and the March of Dimes.
Author information
Authors and Affiliations
Contributions
M.P. and J.N. wrote the initial draft of the manuscript. N.A. made revisions and provided critical intellectual input for the review.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Pammi, M., Aghaeepour, N. & Neu, J. Multiomics, artificial intelligence, and precision medicine in perinatology. Pediatr Res 93, 308–315 (2023). https://doi.org/10.1038/s41390-022-02181-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41390-022-02181-x
This article is cited by
-
Multimodal machine learning for modeling infant head circumference, mothers’ milk composition, and their shared environment
Scientific Reports (2024)
-
Reassessing acquired neonatal intestinal diseases using unsupervised machine learning
Pediatric Research (2024)
-
Emerging role of artificial intelligence, big data analysis and precision medicine in pediatrics
Pediatric Research (2023)
