
Abstract
The structure and mechanism of the human visual system contain rich treasures, and surprising effects can be achieved by simulating the human visual system. In this article, starting from the human visual system, we compare and discuss the discrepancies between the human visual system and traditional machine vision systems. Given the wide variety and large volume of visual information, the use of non-von Neumann structured, flexible neuromorphic vision sensors can effectively compensate for the limitations of traditional machine vision systems based on the von Neumann architecture. Firstly, this article addresses the emulation of retinal functionality and provides an overview of the principles and circuit implementation methods of non-von Neumann computing architectures. Secondly, in terms of mimicking the retinal surface structure, this article introduces the fabrication approach for flexible sensor arrays. Finally, this article analyzes the challenges currently faced by non-von Neumann flexible neuromorphic vision sensors and offers a perspective on their future development.
Similar content being viewed by others

Introduction
With the rapid development of deep learning, existing machine vision systems have achieved a certain level of performance in various areas such as autonomous driving1,2, face recognition3,4, unmanned aerial vehicle (UAV) navigation5,6, industrial inspection7,8, and video surveillance9,10. However, In the face of the demand for high precision and high speed in machine vision systems for complex real-world scenarios (for example, in high-speed motion scenes or under extremely dim conditions), the algorithmic iteration and upgrade of machine vision systems relying on the traditional von Neumann architecture have encountered bottlenecks11. To develop higher-performance machine vision systems, it is necessary to conduct in-depth analysis of the challenges faced by existing machine vision and eliminate the obstacles to improving machine vision performance.
The von Neumann architecture represents a foundational paradigm in computer system design. Its key elements encompass stored programs, a binary system, a central processing unit (CPU), sequential execution, and input/output devices. Within the framework of the von Neumann architecture, the performance of machine vision systems is intricately linked to factors such as optical hardware devices, CPU processing capabilities, memory, and data transfer speed between processors. In essence, to attain elevated performance levels, machine vision systems must grapple with three pivotal challenges.
Firstly, the outstanding performance of machine vision systems largely depends on the effective acquisition of visual data. The more comprehensive and higher quality of the collected data, the better the resulting outcomes are likely to be. This aspect is typically achieved through the use of optoelectronic sensor arrays. Currently, most arrays are designed in a planar fashion, with some limitations compared to curved sensor arrays. Traditional rigid electronics, when transitioning from a two-dimensional plane to three-dimensional space, often encounter failures at bent points due to the compression or even breakage of individual sensors. Introducing flexible electronic devices into machine vision systems reduces the occurrence of failures, thereby obtaining superior visual data.
Secondly, achieving higher performance in machine vision systems requires more advanced algorithms, and these advanced algorithms demand processors with higher capabilities. The performance of an individual processor is typically supported by its integrated density level. However, silicon-based semiconductor technology has reached its limits in keeping up with Moore’s Law12. This means that traditional processors are approaching their maximum capacity. To sustain the development trend of Moore’s Law and enhance processor performance, it is necessary to go beyond the realm of silicon semiconductors and explore new materials.
Lastly, for high-level processors, the efficiency of communication between the processor and storage chips is crucial for fully leveraging the existing performance of the processor13. The diversity and richness of visual information result in large volumes and high complexity of visual data. Under the von Neumann architecture, once the data transfer speed reaches its limit, the system, due to its sequential execution nature, has to wait for the data transfer to complete before proceeding to the next operation. This is critical in fields with high real-time requirements, such as autonomous driving and drone visual navigation.
Addressing all three of these issues simultaneously is quite challenging. Fortunately, nature has provided us with the solution. As the most advanced intelligent beings on Earth, humans process an enormous amount of information every day. As the most vital component of our perceptual system, the human visual system is responsible for perceiving and processing over 80% of the information processed by the human body. In the face of such a vast amount of information, in contrast, the human visual system exhibits superior performance in terms of low redundancy, low power consumption, and strong robustness, which the existing machine vision systems cannot match14. Therefore, as the development of machine vision hardware reaches a bottleneck, reexamining the human visual system and drawing inspiration from its mechanisms for perception and information processing can help in the development of higher-performance machine vision systems. Figure 1 shows a comparison between human visual system, traditional machine vision system, and the flexible non von Neumann machine vision system that this article focuses on.

a Human visual system workflow. b Traditional machine vision system workflow. c Non-von Neumann machine vision system.
Human visual system
The human visual system can be broadly divided into two parts. The first part is the visual information perception module represented by the eyes, and the second part is the visual information processing module represented by the visual cortex in the brain. When light reflected from external objects passes through the optical structures, such as the lens, it stimulates the retina, which is the light-sensitive tissue at the back of the eye. The cells in the retina, including cone cells and rod cells, respond to light stimuli. The visual information is then transmitted through the fibers of the optic nerve, carrying the electrical signals of the light stimuli to the visual cortex in the brain. It is in the visual cortex that the final process of visual perception and cognition takes place.
In the complete visual pathway, the retina plays a dual role in both perception and preprocessing. Therefore, delving into the structure and information-processing mechanisms of the retina is meaningful. This contributes to addressing the first and third challenges. Additionally, efficient data processing methods in the visual cortex should also be considered, aiding in enhancing the computational capabilities of chips.
The curved structure of the retina
From an optical perspective, the retina serves as the imaging screen of the human visual system, taking the form of a concave sphere. Various optical systems, including the eyes, inherently have a fundamental curvature in their field of view, known as the famous Petzval surface15. Consequently, the image field is naturally curved. For flat structures, more lenses are required to correct aberrations. In contrast, a curved structure can address this issue with little or no correction needed. Furthermore, the curved structure of the retina can match the spherical shape of the eye, allowing the visual focus to move without the need to shift the head. This contributes to obtaining a larger perceptual range. Overall, to achieve higher performance, there are many noteworthy details in the “imaging screen” aspect of the human visual system16,17,18,19.
The information processing mechanism of the retina
The retina can preliminarily process visual information. As a crucial component of the photosensitive transduction system, the retina has a well-defined hierarchical structure. As shown in Fig. 2, the retina can be roughly divided into three layers: photoreceptor cells, bipolar cells, and ganglion cells. Horizontal cells and amacrine cells form a network in the horizontal direction of the retina20.

Reproduced under the terms of CC BY 4.0 license20. Copyright 2021, Elsevier.
The photoreceptor cells on the retina convert light signals into electrical signals and transmit them further. The photoreceptor cells on the retina mainly include cone cells and rod cells, corresponding to the cone system (also known as photopic or daylight vision system) and the rod system (also known as scotopic or night vision system), respectively21. The cone system consists of cone cells, bipolar cells that connect to them, and ganglion cells. It has color discrimination ability and high resolution for object details but is less sensitive to light. In contrast, the rod system consists of rod cells, bipolar cells, and ganglion cells. Its characteristics are opposite to the cone system. The coordination between the cone and rod systems allows the human visual system to have excellent visual capabilities in both bright and dim environments.
The dispersed electrical signals obtained after the conversion of light signals by photoreceptor cells are integrated into bipolar cells. In this process, horizontal cells regulate the signal transmission between photoreceptor cells and bipolar cells through lateral inhibition mechanisms, enhancing the perception of edges and contrast22. This marks the starting point of information preprocessing in the retina. The integrated electrical signals, regulated by amacrine cells, are then transmitted to ganglion cells for the encoding of specific features23. It’s worth emphasizing that horizontal cells primarily exist in the outer nuclear layer of the retina, synaptically connected to photoreceptor cells and bipolar cells, participating in bidirectional information transmission, mainly functioning in the early stages of visual signal processing. On the other hand, amacrine cells are distributed throughout various layers of the retina, connected to various neurons (including photoreceptor cells and ganglion cells), participating in the information transmission between photoreceptor cells and ganglion cells, involving higher-level visual processing.
In fact, there are ~30 types of ganglion cells that play a role in the functioning of the retina, allowing it to encode various attributes of the visual scene24. Ganglion cells are mainly classified into Parvocellular cells (P Cells) and Magnocellular cells (M Cells)25. The former are more sensitive to color and high-resolution, detail-rich visual information, while the latter are more sensitive to motion and low-contrast stimuli. This sensitivity is determined by their cell structure, response characteristics, and receptive field size. Both types extract information relevant to their sensitivity from the received light signals and process it in parallel. The corresponding pathways are known as the parvocellular (p) pathway and the magnocellular (m) pathway26. The former is better suited for processing details, color recognition, and static object information, while the latter is more suitable for processing overall motion, depth perception, and sensitivity to dynamic scenes. This aligns with the characteristics of the corresponding cells.
In the perceptual process of the above light signals, signals gradually propagate from photoreceptor cells to higher-level neurons. This hierarchical processing allows the retina to adapt to different lighting conditions, motion scenarios, and complex visual scenes. Moreover, the processing in the retina is achieved through gradient signals, not electrical potentials like in the central nervous system. By detecting and encoding gradient signals, the retina can achieve efficient specificity and accuracy in perceiving visual information. For instance, when there is a sudden change in light intensity or color, gradient signals exhibit significant variations, enabling the retina to precisely locate edges in the image. This is crucial for perceiving the shape and structure of objects. Compared to directly transmitting the overall brightness or color information of the entire image, information transmitted through gradient signals is more compact and precise, facilitating efficient transmission and processing of information in the nervous system. This processing approach provides clear and organized input for subsequent stages of visual processing, allowing the brain to more effectively interpret the visual world.
The data processing mechanism of the visual cortex
The visual cortex is divided into multiple regions, and its mechanisms are continuously being investigated27,28,29, leading to the development of various bio-inspired models and algorithms30,31,32.
During the process of data processing in the human brain, various types of neurons are involved in learning concepts and information transmission. A typical neuron consists of dendrites, cell body, axons, and synapses, with synapses primarily responsible for information transmission. During the transmission process, the presynaptic neuron undergoes changes in electrical potential and releases neurotransmitters. The postsynaptic neuron receives the neurotransmitters, leading to changes in its electrical potential. Many complex logical operations, such as Boolean logic operations33, are performed at the presynaptic terminals before the signal is transmitted to the cell body. The persistent changes in the morphology, function, strength, and efficiency of synapses are referred to as “synaptic plasticity.” Based on the duration of these changes, synaptic plasticity can be divided into short-term plasticity (STP) and long-term plasticity (LTP), corresponding to short-term memory (STM) and long-term memory (LTM) in the human brain34. Brief visual stimuli can activate short-term plasticity synapses, while increasing the frequency, duration, and intensity of visual stimuli can activate long-term plasticity synapses. If such stimulation is actively generated, this process is referred to as experiential learning in the human brain, which is also one of the most significant differences between the human brain and computers35
Discrepancies in human and machine vision systems
Existing machine vision systems are based on the von Neumann architecture, utilizing cameras, memory, processors, and algorithms to perform visual-related tasks. In comparison to the human visual system, these two systems exhibit significant differences in the following aspects:
Sensing and preprocessing module
The sensing module of machine vision systems generally consists of a camera and a photosensitive device. Its purpose is to convert light signals reflected from objects or emitted directly by objects into electrical signals using the photosensitive properties of the device. Typically, the sensing module does not have any additional functions. In contrast, the sensing
part of the human visual system, represented by the retina, not only performs the phototransduction function but also conducts preprocessing of the converted electrical signals. This preprocessing significantly enhances the efficiency of visual data processing. Machine vision systems, on the other hand, require additional preprocessing modules to address this issue. This approach inevitably leads to disadvantages such as highly redundant data and slower processing efficiency. To address this issue, the widely adopted approach in the industry is to maximize the amount of information (“info-max” approach) contained in the input data36. This involves simplifying the quantity of data sent and processed to align with the current capabilities of materials and sensor hardware. While this approach may provide a temporary solution, it might not be a long-term strategy, given the ever-increasing demands on machine vision systems. Undoubtedly, the volume of data will increase with the growing demand, and someday, the amount of data will surpass the maximum threshold that “info-max” approach can handle. After reaching this point, addressing the information bandwidth issue will remain unavoidable.
Furthermore, the photosensitive devices used in machine vision systems are typically two-dimensional flat structures, which inherently have a disadvantage compared to the curved structure of the retina. To focus the light onto the sensor plane, complex multi-lens optical devices are required, posing integration challenges37. At the same time, to shift the visual focus, machine vision systems typically need to move the entire device rather than a single array of photodetectors. This poses a challenge to the durability of machine vision systems. Table 1 provides a comparison of the sensing modules of the two visual systems.
In summary, the retina serves as both the endpoint of human visual perception and the starting point of visual information processing. It accomplishes the tasks that would require separate sensing and preprocessing modules in a machine vision system. The capabilities of the retina and its curved photosensitive structure have clear implications for high-performance machine vision systems. By emulating the functionality of the retina, integrating the information sensing and preprocessing modules into a single module becomes possible. This approach not only reduces the number of components, facilitating device integration, but also minimizes data transmission processes, thereby improving the overall system speed38,39,40.
Overall processing module
Machine vision systems rely on algorithms to process visual information. With the increasing level of everyday demands, there is a wide range of related algorithms available. Among them, the most typical visual algorithm is Convolutional Neural Network (CNN)41,42,43. These types of algorithms are based on Artificial Neural Networks (ANN) and are implemented by adding and improving network structure layers. ANN learns from samples, stores experiences, and simulates the learning process of the human brain. However, this approach focuses more on improving algorithm performance and overlooks the biological plausibility of the algorithm itself44. The human brain processes information through the transmission of pulse signals between synapses. When not receiving corresponding stimuli, the next neural synapse or even the entire region remains inactivated. In contrast, after successful training of an ANN network, all the hidden layer weights are in an activated state, resulting in higher energy consumption. To better describe the differences between the processing modules of the human visual system and the machine vision system, we have compared them in Table 2.
Summary
This section introduced the photoreceptor and processing units of the human visual system and highlighted the shortcomings of machine vision systems in perceiving and processing optical data. To address these shortcomings, the next step can be focused in two directions: taking inspiration from the functionality and structure of the retina and drawing insights from the neural synapses in the brain for algorithm and circuit design.
Mimicking retinal preprocessing function
Traditional neuromorphic vision sensors
Neuromorphic vision, as a visual perception system incorporating hardware, software, and biological neural models, differs from the mainstream direction of machine vision, which follows the paradigm of “video camera + computer + algorithm = machine vision.” Since its introduction, it has garnered widespread attention from industry professionals14. Compared to traditional machine vision systems, the greatest advantage of neuromorphic vision systems lies in their exploration of the biological foundation of vision. They have introduced a novel concept of frameless transient vision sensors, which differs from the frame-based approach commonly used in traditional machine vision systems.
In traditional machine vision, video data is processed based on frames, which leads to the generation of a significant amount of redundant data, limiting the pixel bandwidth. In contrast, neuromorphic vision sensors, based on event- and data-driven principles, discard irrelevant light source information, resulting in a higher-performance machine vision system. These sensors operate by focusing on events and relevant changes in the visual scene, rather than processing entire frames, thereby reducing redundancy and improving efficiency.
The formal introduction of neuromorphic vision sensors into people’s awareness can be traced back to 1991 when Mahowald and Mead created the first silicon retina45. In the pursuit of imitating, approximating, and surpassing the retina in terms of structure, device functionality, and intelligent capabilities, the requirements for neuromorphic vision sensors can be summarized as “smaller, faster, and more intelligent”46. Since the introduction of the first silicon retina, scholars have conducted extensive research on this sensor. In 2005, the Dynamic Vision Sensor (DVS) developed by the Delbruck team marked a milestone in the commercialization of neuromorphic vision sensors47. In 2008, Posh et al.48 introduced the Asynchronous Time-based Image Sensor (ATIS), which demonstrated the possibility of parallel acquisition of static and dynamic image information. In 2013, the Delbruck team developed the Dynamic and Active pixel Vision Sensor (DAVIS) based on the DVS, and later expanded it to the color DAVIS346 in 201749,50. Until now, DVSs are still being developed51.
The aforementioned sensors adopt a differential visual sampling model, mainly simulating the peripheral motion perception function of the retina, while lacking in simulating the fine texture perception function of the central fovea of the retina. However, the octopus retina model52 and the Vidar model53, which use an integrative visual sampling model, demonstrate significant advantages in fine texture perception. Each of these neuromorphic vision sensors has its own advantages, but they share a common drawback: complex circuitry, large pixel area, and low fill factor54.
Although the aforementioned sensors have been widely used in various machine vision and robotics applications, they still face challenges in low integration, high power consumption, and large latency. As sensors based on silicon semiconductor technology, they are also bound by Moore’s Law. At the same time, while they imitate the functionality of the retina at a certain level, their imitation of the structural shape of the retina is minimal.
Non-von Neumann computing architecture
While traditional neuromorphic vision sensors have successfully reduced much of the redundant data, they still face challenges when it comes to real-time applications with high demands for data throughput, such as autonomous driving and UAV visual navigation. In these domains, there is a risk of hitting the memory wall due to the large amount of data that needs to be processed within a short period.
To address this issue, the concept of “non-von Neumann architecture” has captured the attention of relevant researchers. The core idea of this concept involves integrating the foundational matrix operations into specific circuits, endowing sensors with inherent computational capabilities, and reducing the overall amount of information that needs to be transmitted and processed (Fig. 3a)55. If this concept is introduced to the field of machine vision, a novel type of non-von Neumann neuromorphic vision sensor with intrinsic computational abilities emerges. In this device, sensors can not only capture visual information but also perform certain computations, mitigating the performance waste caused by visual information transmission and achieving more efficient processing. Common implementations of non-von Neumann architecture for vision sensors are as follows:

a Comparison between von Neumann and non-von Neumann architectures. Reproduced with permission55. Copyright 2020, Springer Nature. b–d Three typical non-von Neumann architectures. b Non-von Neumann architecture based on analog circuits. Reproduced with permission56. Copyright 2018, Springer Nature. c non-von Neumann architecture based on digital circuits. Reproduced with permission53. Copyright 2020, Springer Nature. Reproduced with permission84. Copyright 2022, John Wiley and Sons. d Non-von Neumann architecture based on optical neural networks. Reproduced under the terms of CC BY 4.0 license90. Copyright 2022, Springer Nature.
Analog circuitry
The concept of resistive crossbar arrays was initially proposed by Bell Labs researchers in the 1960s. Since then, it has evolved and expanded to include V-R logic gates, V-V logic gates, R-R logic gates, and more (Fig. 3b)56. Although the individual resistor device structure in the array may differ from the electrical units utilized (voltage, current, resistance), the basic operating logic of the array remains the same.
Resistive crossbar arrays are computing devices based on resistance modulation at cross-points and are used for matrix multiplication-based computations, making them suitable for various types of neural networks57,58,59,60,61,62,63,64,65,66,67. In this array, resistors serve as switching components. By dynamically adjusting the resistance values at the crosspoints, different weighted multiplication operations can be achieved through the simple application of Kirchhoff’s law and Ohm’s law(Bottom of Fig. 3b). The reuse of resistors for interconnecting neurons enables forward and backward propagation processes in neural networks. Resistive crossbar arrays offer advantages such as high reconFigureurability, high integration density, low power consumption, and strong stability, making them widely applicable in artificial intelligence, analog computing, and biomedical fields.
However, the disadvantages of resistive crossbar arrays are also quite evident. For a completed resistive crossbar array, modifying the weights (resistance values) can be rather challenging. With the rapid development of the materials industry, researchers have discovered certain materials that exhibit memristive effects, wherein the resistance of the material changes under the influence of an electric field or current. This resistance variation is dependent on the applied voltage or current68. Devices fabricated using these materials with memristive properties are known as memristors. Utilizing memristors and their characteristics, memristive neural networks can be constructed, which share similarities with resistive crossbar arrays69,70,71,72,73,74,75,76,77,78,79. Compared to resistive crossbar arrays, memristive neural networks not only exhibit stronger adaptability but also, with memristors serving as non-volatile memory devices, can store weights to achieve integrated storage and computation69,80. Furthermore, compared to traditional computing devices such as CPUs and GPUs, memristive neural networks can significantly reduce power consumption.
Taking the simplest example of a single-layer perceptron, it can be used for classification and recognition of images with nine pixels81. As shown in Fig. 4a, the nine pixels are input as voltages (V1–V9) in the algorithm structure. Additionally, a bias voltage (V10) is also input to update the weights (i.e., resistances at each cross point). The size of the weight matrix, which implements the neural network algorithm, needs to be adjusted according to the specific input-output requirements. Assuming the final output is a three-dimensional vector, the size of the weight matrix would be 10 × 3. The actual circuit is shown in Fig. 4b, where \({G}_{{ij}}\) represents the effective conductance of each resistor. Within one cycle, the weight calculation formula is as follows:

a Pixel information input in the form of voltage, along with bias voltage. b Actual circuit diagram and the training process. c Training results and implementation mode of multi-layer neural network. a, b and left side of c Reproduced with permission81. Copyright 2018, Springer Nature. Right side of c reproduced with permission55. Copyright 2020, Springer Nature.
Afterwards, the obtained signal (or data) is represented in the form of a current and then passed through an activation function for output. The formulas for the activation function are shown as (2) and (3):
In this way, one training process is completed. Since the initial weights may not be correct, a single iteration may not guarantee the desired output. It is necessary to adjust the resistors in the array to achieve weight updates. Taking the letter “Z” as an example, let’s define the voltage of the pixels occupied by the letter as positive and negative otherwise. Following the input pattern shown in Fig. 4b, the weight update \(\Delta {W}_{{ij}}\) is given by the following formula:
After computing \(\Delta {W}_{{ij}}\), it is necessary to modify the weights of each column of the crossbar switch based on the actual situation. This modification can be done by applying a “reset” pulse. The process is repeated continuously until the output reaches the desired accuracy. For a specific resistive crossbar array, different pixel images (i.e., different output signals) will yield different output results. Based on this characteristic, it is possible to achieve classification and recognition for specific letters or characters. It is defined that classification is considered successful when the output signal \({f}_{i}\) corresponding to the correct category for the applied pattern is greater than all other outputs. In this paper, perfect classification was achieved on average after 23 epochs, with a standard deviation of 10 epochs. The final classification results are expressed in the form of currents (Fig. 4c). Expanding this concept further, it can effectively replace each weight layer in complex neural networks55. Furthermore, this can enable the implementation of various types of neural networks82.
Digital circuitry
While the emergence of memristive devices has provided excellent insights for hardware-based neural networks, the current manufacturing and integration technologies for memristors may not yet support large-scale applications within neural networks. Additionally, although analog circuits exhibit rich dynamic characteristics and can simulate the continuous updating of neural network states, there is still a gap in achieving control and communication-related functions compared to digital circuits. Therefore, the recent research focus has also been on how to use digital circuits to implement non-von Neumann computing.
To be frank, the key to achieving non-von Neumann computing lies in using circuits for matrix calculations. The use of logic gates in digital circuits has made this idea a reality. Figure 3c is an example of matrix multiplication using Digital circuitry55. For the input vector [0 1 3 2], it is first converted to binary, resulting in two input binary vectors [0 1 1 0] and [0 0 1 1]. Similarly, the matrix [3 6 2 1] that is multiplied with the input vector is also converted into 3 binary vectors. The two input vectors are multiplied element-wise with the three system state matrix vectors and converted from binary to decimal (which can be achieved using logic gate circuits). Finally, the results are added together to obtain the final output. Building upon this, neural networks can be integrated into hardware. At the bottom of Fig. 3c is a binary image processing circuit83.
Similar to resistive crossbar arrays, circuits made using logic gates also face the challenge of limited adaptability. The current industry-recognized approach for programming logic gate arrays is to use FPGA (field-programmable gate array). As shown in Fig. 5, implementing non-von Neumann computing with FPGA involves five steps: Circuit Modeling, Neuron Simulation and Synaptic Weight Programming, Network Topology and Algorithm Training, Interface Control and Debugging, and Application83,84,85,86. In many hardware circuit implementations of neural networks (essentially non-von Neumann architectures), memristor models play a significant role in the initial circuit element modeling stage. In fact, these digital memristor models only simulate certain aspects of memristor performance, achieving significant computational advantages by avoiding the use of complex mathematical functions83.

Optical neural networks
Optical neural networks are a method that applies optical technology to the implementation of neural networks. By using optical devices to simulate the functions of neurons and their connection weights, it is possible to achieve high-speed and energy-efficient neural network computations.
In the early stages, optical neural networks primarily relied on the photo-tunable synaptic properties of specific materials. As shown in Fig. 6a, compared to the traditional image sensor represented by the red line, transistors with photo-tunable synaptic properties represented by the blue line exhibit a time-dependent response in the relationship between output current and illumination time. This represents the possibility of replicating the mechanism of synaptic plasticity through such responses, ultimately mimicking the learning and memory functions of the human brain87.

a Optical neural network with photo-tunable synaptic properties based on specific materials. Reproduced with permission87. Copyright 2019, Springer Nature. b Optical neural network based on a dual-gate transistor array. Reproduced with permission89. Copyright 2020, Springer Nature. c Optical neural network based on the polarization effect. Reproduced under the terms of CC BY 4.0 license90. Copyright 2022, Springer Nature.
An unsatisfactory aspect of this approach is that such specific materials generally achieve tunable light responsiveness through ion migration, which has a relatively slow rate of migration88. To overcome this drawback, Mennel et al.89 created a dual-gate transistor (Fig. 6b). Each transistor operates in short circuit, with its responsiveness individually set by a pair of gate voltages. They used this array to implement a classifier and an autoencoder. In subsequent work, based on the ref. 81, they recognized images with different signal-to-noise ratios. Experimental results showed that, even with a signal-to-noise ratio of 0.3, the array not only correctly interprets input signals but also significantly improves the noise in the reconstructed images.
The dual-gate transistor effectively enhances the speed of the sensor, but the application of voltage to the gate unavoidably increases power consumption. Currently, gateless, self-powered, reconfigurable optoelectronic sensors have emerged90. What’s even more exciting is that this sensor can not only change the magnitude of the light response but also alter the sign of the light response.
Furthermore, optoelectronic transistors can be connected in series with memristors to form a 1T1R structure58,71,91,92,93,94,95. The intrinsic voltage-current characteristics of the transistor make training of memristive neural networks, especially synaptic weight updates, more controllable. By individually controlling the gate voltage of each transistor, parallel control of the array can be achieved, thus improving training efficiency.
Illustrations of non-von Neumann architecture computations
Applications to second-generation ANNs
Before the concept of memristors emerged, researchers often described circuit components with neural-like computing capabilities as “electronic synapses.” The focus of related work was primarily on implementing non-von Neumann multiplication and accumulation operations using hardware. The limited applicability of these approaches stemmed from the challenge of reliably modifying the conductance states of the devices79. As a consequence, early research endeavors primarily centered on specific circuit designs and their real-world performance.
Sebastian et al.66 presented a method for inference and training of deep neural networks using circuits, along with experimental results using phase-change memory (PCM) devices. The results demonstrated that PCM technology can achieve higher-performance deep neural networks compared to traditional methods. With the continuous improvement of PCM devices in the future, they anticipate even further enhancements in performance; Ambrogio et al.69 demonstrated a hardware-software co-design approach for neural network implementation involving as many as 204,900 synapses. They combined long-term storage in phase-change memories, near-linear updates in volatile capacitors, and weight data transfer with “polarity inversion” to address inter-module communication issues. They achieved generalized accuracy equivalent to software-based training on various commonly used machine learning test datasets (MNIST, MNIST-background, CIFAR-10, and CIFAR-100). Their implementation achieved a computational efficiency of 280.65 trillion operations per watt and a unit area throughput of 3.6 trillion operations per square millimeter per second, surpassing the performance of today’s graphics processing units (GPU) by two orders of magnitude; S.R. Nandakumar et al.79 proposed a mixed-precision architecture that combines computational storage units with high-precision processing units. The core idea of this architecture is to provide classification accuracy comparable to floating-point implementations while overcoming the challenges associated with the non-ideal weight update characteristics of emerging resistive memories. Their experimental results demonstrate that computational storage units implemented with nonlinear stochastic models using phase-change memories achieved a test accuracy of 97.40% in a two-layer neural network for the MNIST digit classification problem.
The emergence of memristors has overcome the limitation of unreliable changes in conductivity states, enabling the development of large-scale hardware circuits with in-sensor computing capabilities. Given the vast amount of visual information data and the simplicity of optoelectronic signal conversion, researchers easily conceived the idea of integrating multiple modules within visual sensors to reduce redundant data and improve data transmission speed. This aligns with the objectives of neuromorphic vision sensors.
Applications to third-generation ANNs
As mentioned earlier, the human brain communicates and processes information through synapses. During the transmission of physiological signals, pulses are the primary mode of conveyance. Hence, obtaining reliable impulse signals and using spiking neural networks to simulate complex human brain behaviors has been a research hotspot in recent years96.
Currently, the majority of research on artificial synapses focuses on simulating static plasticity, while a few controllable synapses based on bipolar transistors (such as shown in Fig. 7a) can regulate the transistor through opposing gate voltages, but still exhibit significant deficiencies in terms of efficiency. The Su Research Group fabricated a p-type transistor based on ferroelectrics-electret synergetic organic synaptic (FEOST), as shown in Fig. 6a97. This device also exhibits pronounced memristive characteristics (Fig. 7b). With the synergistic effect of ferroelectric polarization switching and charge trapping, the device demonstrates two distinct modes under single-gate pulse stimulation, effectively mimicking neural synapse potentiation and inhibition behaviors (Fig. 7c). In their work, they eventually applied this device to a temperature sensor to simulate human temperature perception (Fig. 7d). In a previous study, they also utilized a voltage-programmable ferroelectric transistor array to accomplish recognition of 28 × 28 handwritten digit pixel images in the form of a memristive neural network (Fig. 7e)98.

a p-type transistor based on ferroelectrics-electret synergetic organic synaptic (FEOST). b The memristor characteristics of this device. c Different modes simulating neural synapse potentiation and inhibition behaviors. d Temperature perception. a–d Reproduced with permission97. Copyright 2023, Wiley-VCH. e Neural network for digital pixel image recognition and highlighted weight layer map. Reproduced with permission98. Copyright 2023, IOP Publishing. f Performance characterization. Reproduced with permission99. Copyright 2023, AIP Publishing.
The Su Research Group has conducted extensive research in the field of neuromorphic computing. In 2022, they investigated the voltage-modulated long-term plasticity of perovskite-based memristive synaptic devices. Using a structure similar to Fig. 7e, their device exhibited 40 consecutive conductance reduction states under positive voltage and 30 conductance enhancement states under reverse voltage within 100 cycles(Fig. 7f)99. Compared to previous works, it demonstrated a nonlinearity of <1 and a high accuracy of over 96.7% in continuous resistance adjustment. This offers a promising avenue for non-von Neumann hardware computation in ANNs.
Retinal curvature structure simulation
Currently, significant progress in neuromorphic computing has led to rapid development in the field of “storage and computation integration.” This is helpful for enhancing the performance of machine vision systems. However, from a broader perspective, the retina not only serves the function of preprocessing data but also has photodetection capabilities. Therefore, if machine vision systems could integrate the photodetection module with the processing module, similar to the retina—creating a unified module for sensing, storage, and processing—it would bring tremendous improvement to machine vision systems. To maximize the overall system performance, the optical advantages of the curved structure of the retina also need to be considered. Thus, this chapter will start with photodetectors, explaining how to achieve the fabrication of curved “sensing-storage-computation integrated” devices through materials and manufacturing methods.
Materials
Silicon itself has relatively brittle physical properties and is prone to mechanical deformation over time when made into curved structures. At the same time, The state-of-the-art image sensors using silicon complementary metal-oxide-semiconductor technology have a detection range for light intensity (70 dB) far smaller than the range of natural light intensity (240 dB), which hinders the improvement of machine vision system performance21. In order to further simulate the human visual system, it is necessary to consider using new materials as substitutes for silicon. In order to accurately identify new materials, clear performance indicators are necessary. In the following sections, we will introduce several important parameters used to compare the performance of photodetectors100:
-
(1)
Responsivity (R): defined as the ratio of photocurrent to incident light intensity, indicating the response efficiency of the photodetector to light signals;
-
(2)
Detectivity (D*): it characterizes the weakest light level that the device can detect, determined by the responsivity and noise of the photodetector;
-
(3)
Noise equivalent power (NEP): defined as the signal light power for which the signal-to-noise ratio (SNR) is equal to 1, representing the minimum incident light power that the photodetector can distinguish from noise. A smaller NEP indicates that the device can detect weaker light. It is equal to the reciprocal of Detectivity (D*);
-
(4)
Linear dynamic range (LDR): it describes an illumination intensity range within which the current response of the photodetector is linearly proportional to the light intensity;
-
(5)
Response speed: characterized by its rise time (tr) and fall time (tf) in response to light signals, defined as the time between 10% and 90% of the maximum photocurrent.
In addition, there are requirements for the stretchability of materials when producing curved sensor arrays. Typically, we use Young’s modulus to measure the degree of deformation in materials during tension or compression processes. The unit of Young’s modulus is usually Pascal (Pa) or Megapascal (MPa). It reflects the elastic properties of the material when subjected to force, indicating whether the material can return to its original shape after the external force is removed. A higher Young’s modulus indicates a stiffer material with less deformation ability under external forces; conversely, a lower Young’s modulus implies that the material is more prone to elastic deformation.
These metrics easily bring graphene to mind, and indeed, the reality aligns with this association. In the realm of photodetectors, Xuetao Gan and colleagues created a graphene photodetector doped with metal, exhibiting high responsivity, speed, and broad spectral bandwidth simultaneously101. The detector’s photoresponsivity exceeds 0.1 AW−1. Notably, the detector shows a nearly uniform response in the 1450–1590 nm wavelength range. Xia Wan and others proposed a self-powered, high-performance graphene-enhanced ultraviolet silicon Schottky photodetector102. Leveraging graphene’s unique ultraviolet absorption characteristics, they elevated the internal quantum efficiency of the sensor to over 100%. In the near-ultraviolet and mid-ultraviolet spectral regions, the designed ultraviolet photodetector demonstrated high photoresponsivity (0.2 AW−1), fast time response (5 ns), and a high detectivity (1.6 × 1013 Jones) under zero bias (self-powered) mode, maintaining stable operation two years after fabrication. In the realm of flexible electronics, graphene finds widespread application in flexible logic devices103, flexible tactile sensors104, and bionic devices105.
Despite exhibiting excellent performance in many aspects, graphene still has some drawbacks. Firstly, graphene is a zero-bandgap material, implying that there is no noticeable bandgap in its energy band structure. In photodetectors, materials typically need to have a certain bandgap to achieve controllable photoresponse. Other two-dimensional materials, such as transition metal dichalcogenides (TMDCs), often have tunable bandgaps, making them more suitable for use in optoelectronic devices. Secondly, graphene’s absorption of visible light is weaker than some other materials. In certain application scenarios, especially in optoelectronic devices that require a broader spectrum of light absorption, other materials may have advantages.
Researchers quickly turned their attention to other two-dimensional materials similar to graphene. They were able to achieve the performance metrics mentioned earlier, making it possible to scale the proportion of electronic circuits106. They also hold immense potential for integration with silicon-based read-out/control electronic devices107. In addition to graphene, typical two-dimensional materials include transition metal compounds and perovskites. This article focuses on introducing four materials: WSe2, MoS2, CsPbBr3, and CsPbI3. We briefly summarized the work of some photodetectors based on the above-mentioned two-dimensional materials in Table 3 for reference 102,108,109,110,111,112,113,114,115,116 Additionally, ferroelectric materials have also received significant attention from researchers due to their unique physical properties. In this article, ferroelectric materials will be introduced in two forms: solely using their own properties and in combination with other materials. The citation order below corresponds to the order in Fig. 8.

Reproduced under the terms of CC BY-NC 4.0 license118. Copyright 2020, AAAS. Reproduced under the terms of CC BY 4.0 license119. Copyright 2018, Springer Nature. Reproduced with permission89. Copyright 2020, Springer Nature. Reproduced according to CC BY-NC 4.0 license terms122. Copyright 2020, Springer Nature. Reproduced according to CC BY-NC 4.0 license terms123. Copyright 2020, Springer Nature. Reproduced with permission21. Copyright 2022, Springer Nature. Reproduced according to CC BY-NC 4.0 license terms11. Copyright 2021, Springer Nature. Reproduced with permission126. Copyright 2016, Wiley-VCH. Reproduced according to CC BY-NC 4.0 license terms127. Copyright 2023, Springer Nature. Reproduced with permission128. Copyright 2019, Wiley-VCH. Reproduced with permission132. Copyright 2021, Wiley-VCH. Reproduced with permission133. Copyright 2018, Wiley-VCH.
Photosensitive materials
WSe2
Photodetectors based on WSe2 exhibit a high light-to-dark current ratio of up to 106. These photodetectors have short response times and demonstrate long-term stability and reproducibility. The selective laser doping method used in their fabrication shows promising prospects for future electronic applications117. Wang et al.118 designed an image sensor based on a WSe2/h-BN/Al2O3 heterostructure, as shown in Fig. 8. By applying different voltages to the gate, they were able to mimic the biological functionality of retinal cells (Fig. 9a). They fabricated an array of on-photodetectors (Top-left corner of Fig. 9a) and off-photodetectors (Bottom-left corner of Fig. 9a), resulting in an analog receptive field (RF, Top-right corner of Fig. 9a). RF of bipolar cells plays a crucial role in early processing of visual information by extracting key features to accelerate visual perception in the brain. This indicates that the visual sensor itself can serve as a CNN for image recognition. As a demonstration, they used the letter “N” as the original image (Bottom-right corner of Fig. 9a) and mapped the Difference of Gaussians (DoG) kernel onto the visual sensor while recording the variance of Ioutput in the array and reconstructing the current variance data, resulting in the experimental and simulated letter “N”. It can be observed that the experimental results align well with the simulated results.

a The emulation of the biological functions of retinal cells by the device, the circuitry based on this for simulating receptive fields, and the image recognition results. Reproduced under the terms of CC BY-NC 4.0 license118. Copyright 2020, AAAS. b The photocurrents of the device under different lighting conditions, along with the colour image recognition algorithm based on this and the experimental results. Reproduced under the terms of CC BY 4.0 license119. Copyright 2018, Springer Nature. c The sensor array and its encoding-decoding functionality implementation. Reproduced with permission89. Copyright 2020, Springer Nature.
Seo et al.119 integrated synaptic devices with optical sensor devices to create an Optic-Neural Synaptic (ONS) device. They further demonstrated a WSe2-based consistent structure Optical Neural Network (ONN). The ONS device exhibits different synaptic dynamics based on light conditions (red, green, blue) to simulate the color mixing pattern recognition function in human vision. Figure 8 shows the synaptic device based on h-BN/WSe2 integrated with a photodetector, as well as a simplified circuit and a comparison with the human visual system. Figure 9b displays the long-term potentiation and inhibition curves under dark conditions and illumination with red, green, and blue lights. This feature enables the development of color image recognition algorithms. Testing showed that the ONN achieved approximately 60% higher recognition rate for mixed-color digits compared to the conventional Neural Network (NN).
Mennel and colleagues developed a sensor array containing an ANN using photodiodes89. The array consists of N pixels, with each pixel comprising M sub-pixels, where each sub-pixel corresponds to a photodiode. The photodiodes operate under short-circuit conditions, and various types of ANNs for image processing can be realized by designing different weights. This network can perceive and process optical images in near real-time. A schematic diagram of an individual photodiode is shown in Fig. 8, and the integrated configuration is depicted in Fig. 9c. This type of visual sensor device holds the potential for large-scale integration and offers a variety of algorithms for ultra-fast computer vision applications. As mentioned earlier, they demonstrated both a classifier (similar to the one on the left in Fig. 4c) and an encoding-decoding unit.
MoS2
MoS2, as a soft two-dimensional nanomaterial, is considered one of the candidates for future optoelectronic devices. Unlike graphene, which lacks a bandgap, monolayer MoS2 has a direct bandgap of 1.8 eV and exhibits a high on/off current ratio (ION/IOFF > 108)120. Compared to WSe2, MoS2 also has a higher on/off current ratio by two orders of magnitude. Furthermore, its excellent flexibility and ultrathin thickness contribute to the fabrication of flexible optoelectronic devices121.
In 2017, Changsoon Choi developed a flexible optoelectronic device using MoS2 and graphene (Fig. 8)122. The device exhibited infrared blindness and successfully captured pixelated optical signals. The effectiveness of the proposed soft material and ultrathin device design was validated through theoretical modeling and finite element analysis. They further implanted the device, called a soft retinal implant, onto the retina of mice, and after 9 weeks, the soft retinal implant array maintained its excellent mechanical strain and light response capabilities.
Based on this foundation, in 2020, using the delayed response characteristics of MoS2’s light sensitivity and drawing inspiration from human memory functions, Changsoon Choi developed a curved neuromorphic image sensor array that mimics the simultaneous perception and preprocessing of the retinal surface structure and edge sensing123. After receiving a single pulse of light stimulation, the array’s output current undergoes a mutation and gradually decreases. If subjected to continuous light pulse stimulation, the output current will increase in a sudden manner. When the light stimulation is stopped, the array’s output current slowly returns to its initial state. During the recovery process, if the array continues to receive light stimulation, the output current will increase again based on the magnitude of the remaining photocurrent from the previous cycle (Fig. 10a). This characteristic closely resembles the human process of memory and forgetting. If we analogize the pulse light signals and the array’s output current to the process of human visual perception and sensation, this array simulates the visual and memory characteristics of humans. In other words, the larger the intensity of the light pulse (deeper visual impression) and the higher the frequency of the light pulse (more visual occurrences), the greater the output current of the array (deeper memory). Figure 10b illustrates the concept of image acquisition and neuromorphic preprocessing using the transistor array. A series of continuous noise optical inputs induce weighted photocurrents in each pixel, and the preprocessed image can be obtained by simple mapping of the final photocurrents.

a The light response of an individual transistor, device fabrication methods, and the response and recovery processes at different positions of the device to stimuli. Reproduced according to CC BY-NC 4.0 license terms123. Copyright 2020, Springer Nature. b Schematic diagram of the device for image acquisition and preprocessing of neuromorphic data, along with normalized photocurrent measurements at each pixel. Reproduced according to CC BY-NC 4.0 license terms123. Copyright 2020, Springer Nature. c Dark adaptation and light adaptation of the human retina. Weber’s law is used to describe this process and the emulation of this process by MoS2. Reproduced with permission21. Copyright 2022, Springer Nature.
In 2022, Fuyou Liao reported the adaptability of molybdenum disulfide to changes in light intensity21. As described in Chapter 2, the human visual system uses two different systems in bright and dark environments, and when transitioning between bright and dark scenes, the visual system switches between them (Fig. 10c). Weber’s law can be used to describe this characteristic. The similarity between the photocurrent changes in molybdenum disulfide during the transition between bright and dark scenes, and Weber’s law further demonstrates the feasibility of using molybdenum disulfide as a material to mimic the human visual system and develop novel neuromorphic vision sensors.
CsPbBr3
Perovskite is a class of compounds with a distinctive structure, characterized by the chemical formula ABX3. In this formula, “A” represents a larger cation, “B” denotes a medium-sized cation, and “X” signifies a smaller anion. Perovskite quantum dots, composed of perovskite materials, typically exhibit different optical and electrical properties from traditional perovskites due to their nano-sized dimensions124,125. This article will use these two materials as examples to explore the applications of perovskite-like materials in non-von Neumann neuromorphic vision sensors.
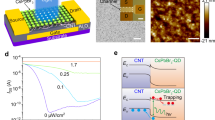
Zhu et al.11 developed a foldable and highly sensitive optoelectronic sensor array for neural-morphic visual systems by incorporating perovskite quantum dots into carbon nanotubes. The array consisted of 1024 pixels and exhibited high integration density, ultra-sensitive detection of visible light, and capabilities for image sensing and biological information processing. The structure of an individual sensor is shown in Fig. 8. The device exploited the energy band difference at the CNT/CsPbBr3-QD interface (Fig. 11a). Its light responsivity is illustrated in Fig. 9f. In their work, the optoelectronic sensor served as an artificial photoreceptor and a biological synapse, directly responding to optical stimulation and performing preprocessing functions with light-tunable synaptic plasticity. Moreover, the device’s response to stimuli of different frequencies and intensities mimicked the process of the human visual system and memory functions in transitioning from unfamiliar to familiar objects.

a Band diagrams of the device in the off state (top) and on state (bottom). Memory characteristics under conditions of constant light intensity with varying pulse numbers and constant pulse numbers with varying light intensity. Reproduced according to CC BY-NC 4.0 license terms11. Copyright 2021, Springer Nature. b Stability of the device under different bending conditions and multiple bending cycles. Reproduced with permission126. Copyright 2016, Wiley-VCH. c Conceptual diagram of the device and its response to red, green, and blue colors. d Filtering function of the device and validation of its effectiveness. Reproduced according to CC BY-NC 4.0 license terms127. Copyright 2023, Springer Nature.
CsPbBr3 can also be assembled into large-area, crack-free, high-quality thin films through simple solution processes (such as inkjet printing or roll-to-roll methods), which is beneficial for the realization of flexible and ultrathin optoelectronic devices. Leveraging this feature, devices prepared using CsPbBr3 not only exhibit excellent optoelectronic performance when bent but also maintain stable responses even after multiple cyclic tests (Fig. 11b)126.
CsPbI3
Zhenghao Long and colleagues used CsPbI3 to fabricate a hemispherical nanowire array retina with neuromorphic and processing capabilities127. They achieved a novel adaptive optical biomimetic eye by integrating it with an artificial crystal lens and a liquid crystal-based electronic iris (Fig. 11c). Due to its hybrid nanostructure, the device exhibits color-dependent bidirectional synaptic light response, addressing the previous limitations in color discrimination ability in research. They used the device for noise filtering and image reconstruction of images with Gaussian noise (SNR of 60%) and pattern recognition through the same CNN. Experimental results showed that after processing with this device, the CNN recognition accuracy improved by ~880% (Fig. 11d).
Computational materials
Ferroelectric materials can undergo polarization under the influence of an applied electric field, and this polarized state can be maintained until stimulated by a reverse electric field or other external conditions. This property indicates that ferroelectric materials have the capability to be used in non-volatile memory devices. Ferroelectric materials typically do not have a single chemical formula since they are a collection of materials with various chemical compositions and crystal structures.
Ferroelectric optoelectronic sensors utilize polarization to adjust their light response, enabling the creation of gateless, self-powered, and reconfigurable optoelectronic sensors, as mentioned earlier. What’s even more exciting is that polarization switching can not only adjust the magnitude of the light response but also reverse the sign of the light response90. This reduces the hardware cost of non-von Neumann computing architectures and enhances the overall device integration.
Neuromorphiccomputing
Jiankun Li fabricated a reproducible ultrathin ferroelectric domain switch, using ferroelectric tunnel junctions (FJTs), for high-performance neuromorphic computing128. The FJTs device features a metal/ferroelectric/semiconductor structure, capable of exhibiting both short-term and long-term plasticity simultaneously (Fig. 8). To demonstrate this, they created a 5 × 5 artificial synaptic array to memorize the letters “I”, “O”, and “P”(Fig. 12a). The array exhibited STM for letters “I” and “P” and LTM for the letter “O.” From the experimental results, it is evident that the letter “I” is quickly forgotten after memorization, while the letter “O” can maintain its memorized state for an extended period. Furthermore, during LTM tasks, the array could still perform STM tasks, and the forgetting of STM did not affect LTM.

a Long and short-term memory characteristics of ferroelectric synapse devices. Letters “I” and “P” represent short-term memory, while letter “O” represents long-term memory. Reproduced with permission128. Copyright 2019, Wiley-VCH. b Associative memory characteristics of ferroelectric synapse devices. Reproduced with permission132. Copyright 2021, Wiley-VCH. c Partial channel conductance of ferroelectric memristor devices; device stability before and after full polarization switching. Reproduced with permission133. Copyright 2018, Wiley-VCH.
Multimaterial synergy
As mentioned earlier, artificial synapses based on FTJs can simultaneously exhibit excellent long-term and STM characteristics. Additionally, there is experimental evidence showing that synapse arrays based on FTJs possess predictable autonomous learning and recognition patterns, contributing to the realization of unsupervised learning in SNNs (Spiking Neural Networks)129. However, the complex fabrication process hinders further development of these arrays130,131. Therefore, ferroelectric materials often appear as gate electrodes in transistors, working in conjunction with other materials to achieve high-performance sensor arrays.
Mengge Yan, inspired by associative memory in the brain, has proposed a ferroelectric synaptic transistor network132. It can recall an entire set of information based on partial data. The device utilizes MoS2 for the channel and ferroelectric materials for the gate dielectric. By establishing new connections between neurons, it can replicate the associative mechanisms of the brain (Fig. 12b). Through circuit design, it can associate items with the places they should appear. What’s more, with a more complex neural network, this device can also perform associations from incomplete pixels to complete ones.
Bobo Tian also using MoS2 as the channel, have developed a low-power organic triple-layer memristor based on a ferroelectric polymer gate insulator133. This memristor exhibits >1000 intermediate states in its conductivity, with a maximum switching ratio of up to 104. This provides ample conditions for the precise updating of neural network weights.
Figure 12c reflects the channel conductivity obtained partially through different gate pulses. The device’s stability performance characterization is also presented in the figure. Although the article does not involve work related to visual stimuli, the presence of MoS2 suggests that it is possible to fabricate this device into a neuromorphic visual sensor.
Fabrication of curved sensor arrays
Traditional machine vision imaging systems are generally composed of planar sensor arrays. However, achieving a breakthrough from a two-dimensional plane to a three-dimensional space involves upgrading the planar array to a curved retina-like array, which helps reduce the complexity of the optical lens module and enables the entire device to have a smaller size. In the early stages, the curved structure was typically made by pre-fabricating the array on a plane and then bending it. This could lead to collisions and compressions of individual photodetectors on the substrate, potentially damaging the overall circuit structure. To address this drawback, Young Min Song et al.134 employed finite element analysis. They simulated the convex planar compound eyes of arthropods to create a curved vision sensor (Fig. 13a). However, it also has some notable disadvantages: in terms of imaging performance alone, the system’s resolution is determined by the number of small eyes, making its overall imaging level only comparable to that of mammals. Moreover, the device is still based on silicon and thus has limitations in terms of stability.

a Insect-inspired convex planar compound eye. Limitations in imaging performance and device stability. Reproduced with permission134. Copyright 2013, Springer Nature. b Simple fabrication methods for flexible electronics and characterization of stretchable, foldable, and stability properties. Reproduced with permission161. Copyright 2013, Wiley-VCH.
The development of electronic skin holds promising prospects for overcoming the challenges faced by vision sensor arrays. Electronic skin is a device inspired by human skin, capable of emulating the stretchability and self-healing properties of human skin135,136,137,138,139. Additionally, due to its ability to interact with humans in various scenarios, the biocompatibility of electronic skin is also crucial140,141,142. Now, electronic skin has been widely applied in various aspects such as simulating tactile perception, proximity sensing, pain perception, temperature sensing, and so on143,144,145,146,147,148. In terms of signal processing, the field of electronic skin also involves neuromorphic computing based on artificial synapses to facilitate extensive data interaction in robotics and prosthetic technologies149,150,151,152,153. For novel neuromorphic vision sensors, in order to achieve device sensitivity, selectivity, stability, and scalability (4 S)154, the fabrication approach of electronic skin holds significant relevance and valuable insights. It should also be noted that MoS2 has applications in both optoelectronic conversion and neuromorphic computing using artificial synapses, indicating a wide range of prospects for the application of MoS2.
In the process of electronic skin fabrication, two common approaches are employed to ensure device stability: geometric pattern design and the use of inherently stretchable materials. Geometric pattern design involves creating wire or electrode structures in shapes that facilitate stretchability, such as serpentine structures155,156,157, to prevent damage to the device during stretching. On the other hand, using inherently stretchable materials involves embedding sensors into a flexible substrate. When the sensor array is subsequently stretched or folded, the flexible substrate demonstrates superior performance compared to rigid substrates158,159,160. In 2013, Chaoyi Yan developed a fully embedded stretchable optoelectronic detector array using PDMS as the substrate161. The fabrication process of this array is straightforward, as nanowires are transferred to PDMS by vacuum suction (Fig. 13b). The optoelectronic response current curves of the sensor array exhibit nearly identical trends across strains ranging from 0% to 100%. It is worth noting that in the mentioned study, individual photodetectors were made of silver nanowires and zinc oxide. This highlights the early efforts of researchers to overcome the limitations of silicon by exploring new materials that are both stretchable and exhibit good optoelectronic properties.
Subsequently, other researchers have conducted studies on enhancing light responsivity during stretching. Traditional flexible processing techniques can be classified into two types: the first type involves using an elastomeric substrate, which is compatible but typically has a rough surface, is hydrophobic, and is susceptible to organic solvents. The second type involves transferring the mixed system onto an elastomeric substrate using a carrier material (PMMA). However, the removal of the carrier material still inevitably requires the use of organic solvents. Additionally, surface adsorbates are often removed, thus compromising the established interface functionality. In the process of PMMA-supported transfer, cracks and wrinkles are unavoidably introduced. Shuyan Qi et al.162 discovered that for MoS2, its poor light responsivity on stretchable substrates is attributed to the inherent low charge carrier density and numerous scattering centers on the substrate. To address this issue, it is necessary to use doping agents with strong air stability on MoS2 while also improving the surface roughness, hydrophobicity, and sensitivity to organic solvents of the polymer. They combined n-type dopant N-DMBI with MoS2, resulting in a stretchable, stable, and highly light-responsive optoelectronic detector. Experimental results demonstrated that through SEBS encapsulation, there was a tendency for electrons to transfer from N-DMBI to MoS2, even after exposure to air for 20 days. Consequently, the charge carrier density significantly increased, enhancing the efficiency of photo-generated electron-hole separation and significantly improving the light responsivity of the MoS2-based optoelectronic detector. Moreover, the sensor maintained high performance even after being stretched 100 times within the stretching limit, exhibiting good stretch durability (Fig. 14a).

a Improved doping agent-based fabrication of stretchable, stable, and highly responsive photodetectors using MoS2. Reproduced with permission162. Copyright 2022, Springer Nature. b Elastiff layer and its stretching state. Performance comparison of flexible electronics with and without the Elastiff layer. Reproduced with permission163. Copyright 2021, Springer Nature.
However, this method still has limitations. The improvement methods they used can only guarantee effectiveness for the material MoS2. For other materials, it may be necessary to seek new doping agents. In order to address this issue more effectively, Weichen Wang et al.163 made structural improvements by adding an Elastiff layer between the substrate and the transistor (Fig. 14b). Essentially, this is an elastic layer with the same composition as the substrate but with a different content. By changing the cross-linking density of the elastomer, this method enhances the stiffness of the local region, thereby reducing strain in the active region of the device. Experimental data indicate that when stretched to 100% strain, the performance of the transistor does not change by more than 5%. A significant improvement in performance can be observed compared to flexible devices without the Elastiff layer.
Integrated applications
A complete bionic eye system is one of the ultimate goals of neuromorphic vision sensors. The performance of a bionic eye system can also intuitively assess the performance of neuromorphic vision sensors. Figure 15 shows two existing bionic eye systems19,164. In terms of material selection, both of them utilized perovskite nanowires and MoS2 for photodetection. They both chose indium coordination to enhance electron migration by exploiting the difference in the Fermi energy level of materials, thereby achieving higher photocurrents. As for the curved surface fabrication step, their methods are quite similar, with only a difference in sequence: Yunxia Hu synthesized MoS2 on a hemispherical quartz substrate using the CVD method, followed by the deposition of indium (In) onto the MoS2 film using a PDMS mask to obtain the curved surface. Leilei Gu, on the other hand, first fabricated a hemispherical porous aluminum oxide membrane (PAM), then employed the CVD method to grow a high-density perovskite nanowire array within the PAM, and subsequently evaporated on the backside of the PAM. Both of these biomimetic phototransduction modules can respond to light in a curved form, as demonstrated in the specific experimental results shown in Fig. 15.

a Schematic illustrating the emulation of the human visual system and the Fermi level diagram of the materials used in the two vision systems. b Fabrication process and light response of System 1 (left in Fig. 15a). Reproduced with permission164. Copyright 2021, Wiley-VCH. c Fabrication process of System 2 (right in Fig. 15a) and image recognition technology. Reproduced with permission19. Copyright 2020, Springer Nature.
Challenges and perspective
Currently, neuromorphic vision sensors are rapidly advancing, and various research achievements continue to emerge. However, on the other hand, the abundance of research outcomes also signifies disorder, as the field of sensor-integrated, storage-capable, and computationally-enabled neural-inspired vision sensors is still in its early stages, lacking a comprehensive visual system framework and standards. Therefore, given the current circumstances, machine vision systems still face numerous challenges to achieve or surpass human visual systems.
Research challenges
Presently, research related to novel neuromorphic vision sensors faces three main challenges:
Research in neuroscience
To further develop novel neuromorphic vision sensors, breakthroughs in neuroscience and neuromorphic research are crucial. This involves understanding and mimicking the perceptual and processing mechanisms of the human visual system. The human retinal ganglion cells, numbering at least 30, encode different attributes within the same visual scene. However, a complete understanding of all ganglion cells is still lacking. Many algorithms are derived from human physiological mechanisms; therefore, a deeper understanding of the human visual system is advantageous for more advanced algorithmic innovations. Additionally, the integration of sensing and preprocessing modules, along with the concept of “storage-computation integration,” is based on the imitation of the human visual system. With progress in neuroscience and neuromorphic research, it becomes possible to unleash the full potential of neuromorphic vision sensors, paving the way for more advanced and intelligent visual perception systems.
Research in materials science
From Table 3, it can be seen that there is a significant variation in the performance of devices made from the same material. This is because the fabrication process of devices often involves doping with other elements or impurities to alter the material’s conductivity. The structure of the device can also have a certain impact on its optical performance. Improving one aspect of performance may lead to a decrease in other aspects. Therefore, based on existing materials, it is necessary to make trade-offs for different scenarios and requirements.
In this review, we introduced two-dimensional materials because transistor arrays made from these materials can meet the requirements in both optical and mechanical performance. Whether there are other materials that are more excellent than two-dimensional materials in these two aspects is still a question worth exploring. This can help us pursue higher performance in machine vision systems. At the same time, achieving tunable bandgaps in functional optoelectronic devices for existing two-dimensional materials is a challenging issue that needs urgent resolution. Additionally, the overall performance of the device is also influenced by other factors such as structure, integration processes, and packaging processes. Most of the photodetectors introduced in this paper were measured in relatively stable laboratory environments, and some even require the use of a vacuum environment. Such conditions are impractical in complex real-world situations. Therefore, it is a significant challenge to ensure that the arrays mentioned in this paper maintain excellent photoelectric response in actual environments, including more adverse conditions.
Research in biological science
After achieving high-performance visual sensors, expanding their applications is also crucial. The flexibility of sensors, allowing them to bend, reduces shear forces at the machine-cell interface, making them promising for wearable devices. In this context, the biocompatibility of the devices becomes paramount. For external wearable devices, it is essential to ensure long-term wear without causing skin redness, inflammation, and other issues due to irritation. This is closely related to the substrate, electrodes, Photonic Materials, packaging processes, and other aspects of visual sensors. For implantable devices, a more comprehensive set of factors needs to be considered. It is not only essential to take into account issues related to cell compatibility (avoiding necrosis of surrounding cells or tissues), immune compatibility (preventing excessive activation of the immune system), and biodegradability (some devices may need to be absorbed after a certain period or removed due to decreased performance, following the “minimally invasive principle”), but also mechanical stability (implantable devices should have sufficient mechanical strength and stability to withstand physiological pressures and movements), performance stability (long-term stable operation), detectability (some implantable devices may need monitoring functions for real-time physiological parameter monitoring), and other practical performance requirements arising from differences between the internal and external environments of the human body.
Research related to SNNs
Research on SNNs has gained significant attention as the third generation of neural networks, relies on the transmission of neural spikes for information processing. SNNs bear a closer resemblance to biological neural networks compared to the second generation of neural networks. Hardware acceleration of SNNs, particularly using FPGAs, can achieve speeds hundreds of times faster than software-based acceleration methods. Consequently, FPGA-based SNN circuit designs have garnered increasing interest in recent years. However, SNNs still face notable shortcomings in various aspects, including neural models, training algorithms, programming frameworks, and datasets. Overcoming these limitations and making progress in these areas would contribute to the development of research on complex computing systems that emulate the human brain. This, in turn, would enhance the overall performance of machine vision systems based on neuromorphic vision sensors. By advancing SNN research in the aforementioned aspects, we can pave the way for the development of sophisticated computational systems that simulate the human brain, ultimately improving the performance of machine vision systems based on neuromorphic vision sensors.
Establishment of new industrial processes and evaluation system
In the present era, we have reached the limitations of Moore’s Law, and traditional semiconductor material, silicon, faces constraints due to its inherent physical properties. It has limitations in terms of flexibility, optical sensitivity, and spectral range, which hinder the further development of machine vision systems. While there have been numerous research efforts showcasing promising alternative optoelectronic semiconductor materials to replace silicon, there still exists a significant gap in terms of overall fabrication processes compared to silicon. Therefore, establishing a comprehensive industrial process and evaluation system is crucial. By addressing these aspects and establishing a comprehensive industrial process and evaluation system, the development and adoption of new optoelectronic semiconductor materials can be accelerated, fostering the advancement of machine vision systems and overcoming the limitations posed by traditional silicon-based technology.
Future directions
Higher-performance “sense-memory-compute integrated” chips
Computational neuroscience with neural morphology computation exhibits significant advantages in terms of computational efficiency and speed. Therefore, it is well-suited for processing visual data characterized by large data volumes and diverse data types. In fields that require high real-time performance, accuracy, and robustness, such as autonomous driving and UAV visual navigation, the concept of “sense-memory-compute integrated” chips can fully leverage its strengths. It holds the potential to provide a superior visual information processing approach compared to traditional machine vision systems.
Retinal prosthesis
The existing retinal prostheses are also based on silicon-based optoelectronic applications. Therefore, they face challenges related to the limited light sensitivity range, brittleness, and high hardness of silicon. When applied to retinal prostheses, there are issues such as a limited color perception range, susceptibility to mechanical deformation during long-term use, and the inability to implant larger areas of the retina prosthesis due to technological limitations. The concept of neuromorphic vision sensors, which aims to mimic the biological retina, along with the use of new materials with a broader light sensitivity range and flexible sensor arrays that can be folded and implanted into the eye, holds the potential to replace silicon-based retinal prostheses and significantly improve postoperative visual experience for patients. In fact, the feasibility of this development direction has been preliminarily demonstrated in the experiment mentioned in Ref. 122.
Integrated storage and computing in multi-system
The information preprocessed by the human retina not only provides input signals to the visual cortex but also serves as input signals for other parts. For example, under different light intensities, the collaborative action between the retina and the autonomic nervous system can cause the pupils to dilate or constrict. This implies that the same set of information can be used by different systems, adapting collectively to the external environment with the coordination of multiple systems. Moreover, the human body is a complex system. In addition to visual perception, external information is received through various sensory modalities such as touch, smell, and hearing. Achieving a higher sensitivity to perceive the external world requires the collective interaction of multiple modalities. Multimodal fusion not only enhances the robustness of the system but also improves its ability to distinguish similar stimuli. For humanoid robots, especially in the context of human-machine interaction, multimodal perception has greater vitality than unimodal perception. However, facing such a vast amount of data, the challenges mentioned in the article regarding traditional computer systems become more apparent. “Storage-Compute Integration” is an excellent solution to address this challenge.
Data availability
All the data are available within the article or available from the authors upon reasonable request.
References
Fang, J. et al. Augmented LiDAR simulator for autonomous driving. IEEE Robot. Autom. Lett. 5, 1931–1938 (2020).
Sun, M., Wang, Y., Li, T., Lv, J. & Wu, J. Vehicle counting in crowded scenes with multi-channel and multi-task convolutional neural networks. J. Vis. Commun. Image Represent. 49, 412–419 (2017).
Ge, Y., Liu, H., Du, J., Li, Z. & Wei, Y. Masked face recognition with convolutional visual self-attention network. Neurocomputing 518, 496–506 (2023).
Liao, M., Fan, X., Li, Y. & Gao, M. Noise-related face image recognition based on double dictionary transform learning. Inf. Sci. 630, 98–118 (2023).
Maravall, D., de Lope, J. & Pablo Fuentes, J. Vision-based anticipatory controller for the autonomous navigation of an UAV using artificial neural networks. Neurocomputing 151, 101–107 (2015).
Meng, Y., Wang, W., Han, H. & Ban, J. A visual/inertial integrated landing guidance method for UAV landing on the ship. Aerosp. Sci. Technol. 85, 474–480 (2019).
Kou, X., Liu, S., Cheng, K. & Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 182, 109454 (2021).
Yao, Z. et al. Inspection of exterior substance on high-speed train bottom based on improved deep learning method. Measurement 163, 108013 (2020).
Kim, H., Kim, K. & Kim, H. Data-driven scene parsing method for recognizing construction site objects in the whole image. Autom. Constr. 71, 271–282 (2016).
Chian, E., Fang, W., Goh, Y. M. & Tian, J. Computer vision approaches for detecting missing barricades. Autom. Constr. 131, 103862 (2021).
Zhu, Q. B. et al. A flexible ultrasensitive optoelectronic sensor array for neuromorphic vision systems. Nat. Commun. 12, 1798 (2021).
Khan, H. N., Hounshell, D. A. & Fuchs, E. R. H. Science and research policy at the end of Moore’s law. Nat. Electron. 1, 14–21 (2018).
Huang, X., Liu, C., Jiang, Y. G. & Zhou, P. In-memory computing to break the memory wall. Chin. Phys. B 29, 078504 (2020).
Li, J. & Tian, Y. Recent advances in neuromorphic vision sensors: a survey. Chin. J. Comput. 44, 1258–1286 (2021).
Xu, F., Huang, W., Liu, J. & Pang, W. Design of lenses with curved Petzval image surfaces. J. Mod. Opt. 63, 2211–2219 (2016).
Zhang, K. et al. Origami silicon optoelectronics for hemispherical electronic eye systems. Nat. Commun. 8, 1782 (2017).
Rao, Z. et al. Curvy, shape-adaptive imagers based on printed optoelectronic pixels with a kirigami design. Nat. Electron. 4, 513–521 (2021).
Ko, H. C. et al. A hemispherical electronic eye camera based on compressible silicon optoelectronics. Nature 454, 748–753 (2008).
Gu, L. et al. A biomimetic eye with a hemispherical perovskite nanowire array retina. Nature 581, 278–282 (2020).
Zheng, Y., Jia, S., Yu, Z., Liu, J. K. & Huang, T. Unraveling neural coding of dynamic natural visual scenes via convolutional recurrent neural networks. Patterns 2, 100350 (2021).
Liao, F. et al. Bioinspired in-sensor visual adaptation for accurate perception. Nat. Electron. 5, 84–91 (2022).
Chaya, T. et al. Versatile functional roles of horizontal cells in the retinal circuit. Sci. Rep. 7, 5540 (2017).
Balasubramanian, R. & Gan, L. Development of retinal amacrine cells and their dendritic stratification. Curr. Ophthalmol. Rep. 2, 100–106 (2014).
Sanes, J. R. & Masland, R. H. The types of retinal ganglion cells: current status and implications for neuronal classification. Annu. Rev. Neurosci. 38, 221–246 (2015).
Croner, L. J. & Kaplan, E. Receptive fields of P and M ganglion cells across the primate retina. Vis. Res. 35, 7–24 (1995).
Masri, R. A., Grünert, U. & Martin, P. R. Analysis of parvocellular and magnocellular visual pathways in human retina. J. Neurosci. 40, 8132–8148 (2020).
Larsson, J. & Heeger, D. J. Two retinotopic visual areas in human lateral occipital cortex. J. Neurosci. 26, 13128–13142 (2006).
Kremkow, J. & Alonso, J. M. Thalamocortical circuits and functional architecture. Annu Rev. Vis. Sci. 4, 263–285 (2018).
Spitzer, H., Desimone, R. & Moran, J. Increased attention enhances both behavioral and neuronal performance. Science 240, 338–340 (1988).
St-Yves, G., Allen, E. J., Wu, Y., Kay, K. & Naselaris, T. Brain-optimized deep neural network models of human visual areas learn non-hierarchical representations. Nat. Commun. 14, 3329 (2023).
Davoodi, P., Ezoji, M. & Sadeghnejad, N. Classification of natural images inspired by the human visual system. Neurocomputing 518, 60–69 (2023).
Chen, G., Scherr, F. & Maass, W. A data-based large-scale model for primary visual cortex enables brain-like robust and versatile visual processing. Sci. Adv. 8, eabq7592 (2022).
Sagi, D. Perceptual learning in vision research. Vis. Res. 51, 1552–1566 (2011).
Kornijcuk, V. et al. Multiprotocol-induced plasticity in artificial synapses. Nanoscale 6, 15151–15160 (2014).
Zhang, C. et al. Synaptic plasticity and learning behaviours in flexible artificial synapse based on polymer/viologen system. J. Mater. Chem. C. 4, 3217–3223 (2016).
Lin, D. & Tang, X. Conditional Infomax Learning: An Integrated Framework for Feature Extraction and Fusion, Computer Vision – ECCV 2006, 68–82 (2006).
Itonaga, K. et al. In: 2014 Symposium on VLSI Technology (VLSI-Technology): Digest of Technical Papers. 1–2 (2014).
Burr, G. W. et al. Neuromorphic computing using non-volatile memory. Adv. Phys. 2, 89–124 (2017).
Zidan, M. A., Strachan, J. P. & Lu, W. D. The future of electronics based on memristive systems. Nat. Electron. 1, 22–29 (2018).
Chai, Y. In-sensor computing for machine vision. Nature 579, 32–33 (2020).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Hou, Y., Wang, X. F., Lang, Z. Q. & Zhao, W. In: 2019 IEEE/CVF international conference on computer vision (ICCV), 21, 1013–1019. (2018)
Heaven, D. Why deep-learning AIs are so easy to fool. Nature 574, 163–166 (2019).
Mahowald, M. In: An analog VLSI system for stereoscopic vision (ed Misha M.) 4–65 (Springer US, 1994).
Cho, S. W., Jo, C., Kim, Y. H. & Park, S. K. Progress of materials and devices for neuromorphic vision sensors. Nano-Micro Lett. 14, 203 (2022).
Lichtsteiner, P., Posch, C. & Delbruck, T. A 128×128 120 dB 15μs latency asynchronous temporal contrast vision sensor. IEEE J. Solid-State Circuits 43, 566–576 (2008).
Posch, C. et al. Live demonstration: asynchronous time-based image sensor (ATIS) camera with full-custom AE processor. In: Proceedings of 2010 IEEE international symposium on circuits and systems, 1392–1392 (2010).
Brandli, C., Berner, R., Minhao Yang, Y., Shih-Chii liu, L. & Delbruck, T. A 240 × 180 130 dB 3 µs latency global shutter spatiotemporal vision sensor. IEEE J. Solid-State Circuits 49, 2333–2341 (2014).
Moeys, D. P. et al. A sensitive dynamic and active pixel vision sensor for color or neural imaging applications. IEEE Trans. Biomed. Circuits Syst. 12, 123–136 (2018).
Tan, H. & van Dijken, S. Dynamic machine vision with retinomorphic photomemristor-reservoir computing. Nat. Commun. 14, 2169 (2023).
Culurciello, E., Etienne-Cummings, R. & Boahen, K. A. A biomorphic digital image sensor. IEEE J. Solid-State Circuits 38, 281–294 (2003).
Dong, S., Huang, T. & Tian, Y. In: 2017 data compression conference (DCC) 437–437 (2017).
Liao, F., Zhou, F. & Chai, Y. Neuromorphic vision sensors: principle, progress and perspectives. J. Semicond. 42, 013105 (2021).
Sebastian, A., Le Gallo, M., Khaddam-Aljameh, R. & Eleftheriou, E. Memory devices and applications for in-memory computing. Nat. Nanotechnol. 15, 529–544 (2020).
Ielmini, D. & Wong, H. S. P. In-memory computing with resistive switching devices. Nat. Electron. 1, 333–343 (2018).
Gokmen, T., Onen, M. & Haensch, W. Training deep convolutional neural networks with resistive cross-point devices. Front. Neurosci. 11, 538 (2017).
Li, C. et al. Analogue signal and image processing with large memristor crossbars. Nat. Electron. 1, 52–59 (2018).
Graves, A. et al. Hybrid computing using a neural network with dynamic external memory. Nature 538, 471–476 (2016).
Alibart, F., Zamanidoost, E. & Strukov, D. B. Pattern classification by memristive crossbar circuits using ex situ and in situ training. Nat. Commun. 4, 2072 (2013).
Burr, G. W. et al. Experimental demonstration and tolerancing of a large-scale neural network (165 000 synapses) using phase-change memory as the synaptic weight element. IEEE Trans. Electron Devices 62, 3498–3507 (2015).
Yao, P. et al. Face classification using electronic synapses. Nat. Commun. 8, 15199 (2017).
Linn, E., Rosezin, R., Tappertzhofen, S., Böttger, U. & Waser, R. Beyond von Neumann–logic operations in passive crossbar arrays alongside memory operations. Nanotechnology 23, 305205 (2012).
Gokmen, T. & Vlasov, Y. Acceleration of deep neural network training with resistive cross-point devices: design considerations. Front. Neurosci. 10, 333 (2016).
Wang, Z. et al. Resistive switching materials for information processing. Nat. Rev. Mater. 5, 173–195 (2020).
Sebastian, A. et al. In: 2019 symposium on VLSI technology. T168-T169 (2019).
Agarwal, S. et al. In: 2017 symposium on VLSI technology. T174-T175 (2017).
Chua, L. Resistance switching memories are memristors. Appl. Phys. A 102, 765–783 (2011).
Jeong, D. S., Kim, K. M., Kim, S., Choi, B. J. & Hwang, C. S. Memristors for energy-efficient new computing paradigms. Adv. Electron, Mater. 2, 1600090 (2016)
Yao, P. et al. Fully hardware-implemented memristor convolutional neural network. Nature 577, 641–646 (2020).
Li, C. et al. Efficient and self-adaptive in-situ learning in multilayer memristor neural networks. Nat. Commun. 9, 2385 (2018).
Ambrogio, S. et al. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature 558, 60–67 (2018).
Liu, S., Wang, Y., Fardad, M. & Varshney, P. K. A memristor-based optimization framework for artificial intelligence applications. IEEE Circuits Syst. Mag. 18, 29–44 (2018).
Wang, T.-Y. et al. Reconfigurable optoelectronic memristor for in-sensor computing applications. Nano Energy 89, 106291 (2021).
Lee, D. et al. In-sensor image memorization and encoding via optical neurons for bio-stimulus domain reduction toward visual cognitive processing. Nat. Commun. 13, 5223 (2022).
Kim, K. H. et al. A functional hybrid memristor crossbar-array/CMOS system for data storage and neuromorphic applications. Nano Lett. 12, 389–395 (2012).
Park, S. et al. Electronic system with memristive synapses for pattern recognition. Sci. Rep. 5, 10123 (2015).
van de Burgt, Y., Melianas, A., Keene, S. T., Malliaras, G. & Salleo, A. Organic electronics for neuromorphic computing. Nat. Electron. 1, 386–397 (2018).
Nandakumar, S. R. et al. In: 2018 IEEE international symposium on circuits and systems (ISCAS). 1–5 (2018).
Wang, H. et al. A ferroelectric/electrochemical modulated organic synapse for ultraflexible, artificial visual-perception system. Adv. Mater. 30, e1803961 (2018).
Prezioso, M. et al. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature 521, 61–64 (2015).
Huang, H.-M., Wang, Z., Wang, T., Xiao, Y. & Guo, X. Artificial neural networks based on memristive devices: from device to system. Adv. Intell. Syst. 61, 060423 (2018).
Zhang, Z., Li, C., Zhang, W., Zhou, J. & Liu, G. An FPGA-based memristor emulator for artificial neural network. Microelectron. J. 131, 105639 (2023).
Zhang, Z., Xu, A., Ren, H. T., Liu, G. & Cheng, X. Reconfigurable multivalued memristor FPGA model for digital recognition. Int. J. Circuit Theory Appl. 50, 3846–3860 (2022).
Tolba, M. F. et al. IP core implementation for analog and digital applications. In: IEEE transactions on circuits and systems II: express briefs 66, 1381–1385 (2019).
Truong-Tuan, V. et al. In: 2021 19th IEEE international new circuits and systems conference (NEWCAS) 1–4 (2021).
Zhou, F. et al. Optoelectronic resistive random access memory for neuromorphic vision sensors. Nat. Nanotechnol. 14, 776–782 (2019).
Chen, Q. et al. Switchable perovskite photovoltaic sensors for bioinspired adaptive machine vision. Adv. Intell. Syst. 2. 2000122 2020)
Mennel, L. et al. Ultrafast machine vision with 2D material neural network image sensors. Nature 579, 62–66 (2020).
Cui, B. et al. Ferroelectric photosensor network: an advanced hardware solution to real-time machine vision. Nat. Commun. 13, 1707 (2022).
Xia, Q. & Yang, J. J. Memristive crossbar arrays for brain-inspired computing. Nat. Mater. 18, 309–323 (2019).
Li, C. et al. Long short-term memory networks in memristor crossbar arrays. Nat. Mach. Intell. 1, 49–57 (2019).
Sheridan, P. M. et al. Sparse coding with memristor networks. Nat. Nanotechnol. 12, 784–789 (2017).
Zhang, W. et al. Neuro-inspired computing chips. Nat. Electron. 3, 371–382 (2020).
Chen, Y. Y. et al. Endurance/retention trade-off on HfO2\metal cap 1T1R bipolar RRAM. In: IEEE transactions on electron devices 60, 1114–1121 (2013).
Wang, F. et al. A two-dimensional mid-infrared optoelectronic retina enabling simultaneous perception and encoding. Nat. Commun. 14, 1938 (2023).
Bu, Y. et al. Ferroelectrics‐electret synergetic organic artificial synapses with single‐polarity driven dynamic reconfigurable modulation. Adv. Funct. Mater. 33, 2213741 (2023).
Bu, Y., Su, J., Li, H., Chen, D. & Xu, T. Ultrathin AlO(x)layer modified ferroelectric organic field-effect transistor for artificial synaptic characteristics. Nanotechnology 34, 31 (2023).
Zhang, J. et al. Voltage modulated long-term plasticity in perovskite heterostructured memristive synaptic devices with high-performance neuromorphic computing. J. Appl. Phys. 133, 044502 (2023)
Wang, H. & Kim, D. H. Perovskite-based photodetectors: materials and devices. Chem. Soc. Rev. 46, 5204–5236 (2017).
Gan, X. et al. Chip-integrated ultrafast graphene photodetector with high responsivity. Nat. Photonics 7, 883–887 (2013).
Wan, X. et al. A self-powered high-performance graphene/silicon ultraviolet photodetector with ultra-shallow junction: breaking the limit of silicon? npj 2D Mater. Appl. 1, 4 (2017).
Jang, H. et al. Graphene-based flexible and stretchable electronics. Adv. Mater. 28, 4184–4202 (2016).
Chen, S., Jiang, K., Lou, Z., Chen, D. & Shen, G. Recent developments in graphene‐based tactile sensors and E‐skins. Adv. Mater. Technol. 3, 1700248 (2018).
Kadumudi, F. B. et al. The manufacture of unbreakable bionics via multifunctional and self-healing silk-graphene hydrogels. Adv. Mater. 33, e2100047 (2021).
Liu, C. et al. Two-dimensional materials for next-generation computing technologies. Nat. Nanotechnol. 15, 545–557 (2020).
Wang, S., Liu, X. & Zhou, P. The Road for 2D Semiconductors in the Silicon Age. Adv. Mater. 34, e2106886 (2022).
Pradhan, N. R. et al. High photoresponsivity and short photoresponse times in few-layered WSe2 transistors. ACS Appl. Mater. Interfaces 7, 12080–12088 (2015).
Tang, Y. et al. WSe(2) photovoltaic device based on intramolecular p-n junction. Small 15, e1805545 (2015).
Luo, M., Wu, F., Long, M. & Chen, X. WSe(2)/Au vertical Schottky junction photodetector with low dark current and fast photoresponse. Nanotechnology 29, 444001 (2018).
Wang, L. et al. MoS2/Si heterojunction with vertically standing layered structure for ultrafast, high‐detectivity, self‐driven visible–near infrared photodetectors. Adv. Funct. Mater. 25, 2910–2919 (2015).
Zhang, W. et al. High-gain phototransistors based on a CVD MoS(2) monolayer. Adv. Mater. 25, 3456–3461 (2013).
Lopez-Sanchez, O., Lembke, D., Kayci, M., Radenovic, A. & Kis, A. Ultrasensitive photodetectors based on monolayer MoS2. Nat. Nanotechnol. 8, 497–501 (2013).
Li, X. et al. Healing all‐inorganic perovskite films via recyclable dissolution–recyrstallization for compact and smooth carrier channels of optoelectronic devices with high stability. Adv. Funct. Mater. 26, 5903–5912 (2016).
Shan, Q. et al. All-inorganic quantum-dot light-emitting diodes based on perovskite emitters with low turn-on voltage and high humidity stability. J. Mater. Chem. C. 5, 4565–4570 (2017).
Du, Z. et al. CsPbI3 nanotube photodetectors with high detectivity. Small 15, e1905253 (2019)
Chen, J. et al. High-performance WSe(2) photodetector based on a laser-induced p-n Junction. ACS Appl. Mater. Interfaces 11, 43330–43336 (2019).
Wang, C.-Y. et al. Gate-tunable van der Waals heterostructure for reconfigurable neural network vision sensor. Sci. Adv. 6, eaba6173 (2020).
Seo, S. et al. Artificial optic-neural synapse for colored and color-mixed pattern recognition. Nat. Commun. 9, 5106 (2018).
Sheng, Y. et al. Gate stack engineering in MoS2 field‐effect transistor for reduced channel doping and hysteresis effect. Adv. Electronic Mater. 7, 2000395 (2021)
Song, J.-K., Kim, M. S., Yoo, S., Koo, J. H. & Kim, D.-H. Materials and devices for flexible and stretchable photodetectors and light-emitting diodes. Nano Res. 14, 2919–2937 (2021).
Choi, C. et al. Human eye-inspired soft optoelectronic device using high-density MoS(2)-graphene curved image sensor array. Nat. Commun. 8, 1664 (2017).
Choi, C. et al. Curved neuromorphic image sensor array using a MoS(2)-organic heterostructure inspired by the human visual recognition system. Nat. Commun. 11, 5934 (2020).
Ning, Z. et al. Quantum-dot-in-perovskite solids. Nature 523, 324–328 (2015).
Rakshit, S., Piatkowski, P., Mora‐Seró, I. & Douhal, A. Combining perovskites and quantum dots: synthesis, characterization, and applications in solar cells, LEDs, and photodetectors. Adv. Opt. Mater. 10, 2102566 (2022).
Song, J. et al. Monolayer and few-layer all-inorganic perovskites as a new family of two-dimensional semiconductors for printable optoelectronic devices. Adv. Mater. 28, 4861–4869 (2016).
Long, Z. et al. A neuromorphic bionic eye with filter-free color vision using hemispherical perovskite nanowire array retina. Nat. Commun. 14, 1972 (2023).
Li, J. et al. Reproducible ultrathin ferroelectric domain switching for high-performance neuromorphic computing. Adv. Mater. 32, e1905764 (2020).
Boyn, S. et al. Learning through ferroelectric domain dynamics in solid-state synapses. Nat. Commun. 8, 14736 (2017).
Choi, K. J. et al. Enhancement of ferroelectricity in strained BaTiO3 thin films. Science 306, 1005–1009 (2004).
Fong, D. D. et al. Stabilization of monodomain polarization in ultrathin PbTiO3 films. Phys. Rev. Lett. 96, 127601 (2006).
Yan, M. et al. Ferroelectric synaptic transistor network for associative memory. Adv. Electronic Mater. 7, 2001276 (2021)
Tian, B. et al. A robust artificial synapse based on organic ferroelectric polymer. Adv. Electronic Mater. 5, 1970006 (2019)
Song, Y. M. et al. Digital cameras with designs inspired by the arthropod eye. Nature 497, 95–99 (2013).
Tang, J. et al. Low power flexible monolayer MoS(2) integrated circuits. Nat. Commun. 14, 3633 (2023).
Li, N. et al. Large-scale flexible and transparent electronics based on monolayer molybdenum disulfide field-effect transistors. Nat. Electron. 3, 711–717 (2020).
Wang, B. et al. Flexible and stretchable metal oxide nanofiber networks for multimodal and monolithically integrated wearable electronics. Nat. Commun. 11, 2405 (2020).
Yang, J. C. et al. Electronic skin: recent progress and future prospects for skin-attachable devices for health monitoring, robotics, and prosthetics. Adv. Mater. 31, e1904765 (2019).
Kim, S. M. et al. Superior toughness and fast self-healing at room temperature engineered by transparent elastomers. Adv. Mater. 30, 1705145 (2018).
Chen, S. et al. Mechanically and biologically skin-like elastomers for bio-integrated electronics. Nat. Commun. 11, 1107 (2020).
Chong, J. et al. Highly conductive tissue-like hydrogel interface through template-directed assembly. Nat. Commun. 14, 2206 (2023).
Wang, R. et al. Holistically engineered polymer-polymer and polymer-ion interactions in biocompatible polyvinyl alcohol blends for high-performance triboelectric devices in self-powered wearable cardiovascular monitorings. Adv. Mater. 32, e2002878 (2020).
Sundaram, S. et al. Learning the signatures of the human grasp using a scalable tactile glove. Nature 569, 698–702 (2019).
Jin, M. L. et al. An ultrasensitive, visco-poroelastic artificial mechanotransducer skin inspired by Piezo2 protein in mammalian merkel cells. Adv. Mater. 29, 1605973 (2017).
Zhang, Y. et al. Dual-mode electronic skin with integrated tactile sensing and visualized injury warning. ACS Appl. Mater. Interfaces 9, 37493–37500 (2017).
Hua, Q. et al. Skin-inspired highly stretchable and conformable matrix networks for multifunctional sensing. Nat. Commun. 9, 244 (2018).
Ge, J. et al. A bimodal soft electronic skin for tactile and touchless interaction in real time. Nat. Commun. 10, 4405 (2019).
Kim, C.-C., Lee, H.-H., Oh, K. H. & Sun, J.-Y. Highly stretchable, transparent ionic touch panel. Science 353, 682–687 (2016).
Lu, Q. et al. Bio-inspired flexible artificial synapses for pain perception and nerve injuries. npj Flex. Electron. 4, 3 (2020).
Kuehn, J. & Haddadin, S. An artificial robot nervous system to teach robots how to feel pain and reflexively react to potentially damaging contacts. IEEE Robot. Autom. Lett. 2, 72–79 (2017).
Wang, S. et al. A MoS(2) /PTCDA hybrid heterojunction synapse with efficient photoelectric dual modulation and versatility. Adv. Mater. 31, e1806227 (2019).
John, R. A. et al. Ionotronic halide perovskite drift-diffusive synapses for low-power neuromorphic computation. Adv. Mater. 30, e1805454 (2018).
Osborn, L. E. et al. Prosthesis with neuromorphic multilayered e-dermis perceives touch and pain. Sci. Robot. 3, eaat3818 (2018).
Jin, M. L. et al. Scalable superior chemical sensing performance of stretchable ionotronic skin via a pi-hole receptor effect. Adv. Mater. 33, e2007605.
Gonzalez, M. et al. Design of metal interconnects for stretchable electronic circuits. Microelectron. Reliab. 48, 825–832 (2008).
Jang, H. et al. Graphene e-tattoos for unobstructive ambulatory electrodermal activity sensing on the palm enabled by heterogeneous serpentine ribbons. Nat. Commun. 13, 6604 (2022).
Xu, S. et al. Stretchable batteries with self-similar serpentine interconnects and integrated wireless recharging systems. Nat. Commun. 4, 1543 (2013).
Yan, C. et al. Highly stretchable piezoresistive graphene-nanocellulose nanopaper for strain sensors. Adv. Mater. 26, 2022–2027 (2014).
Kim, T. Y. et al. Transparent large-area MoS(2) phototransistors with inkjet-printed components on flexible platforms. ACS Nano 11, 10273–10280 (2017).
Chortos, A. et al. Highly stretchable transistors using a microcracked organic semiconductor. Adv. Mater. 26, 4253–4259 (2014).
Yan, C. et al. An intrinsically stretchable nanowire photodetector with a fully embedded structure. Adv. Mater. 26, 943–950 (2014).
Qi, S. et al. N-doped MoS2 via assembly transfer on an elastomeric substrate for high-photoresponsivity, air-stable and stretchable photodetector. Nano Res. 15, 9866–9874 (2022).
Wang, W. et al. Strain-insensitive intrinsically stretchable transistors and circuits. Nat. Electron. 4, 143–150 (2021).
Hu, Y. et al. Ultralow power optical synapses based on MoS(2) layers by indium-induced surface charge doping for biomimetic eyes. Adv. Mater. 33, e2104960 (2021).
Acknowledgements
The work was financially supported by the Young Taishan Scholars Program of Shandong Province (grant nos. 201909099) to M.L. Jin, Ministry of Education, Singapore, under its Research Centre of Excellence award to the Institute for Functional Intelligent Materials (I-FIM, project No. EDUNC-33-18-279-V12) to S.S. Ge, and National Natural Science Foundation of China (grant nos. 52003134 and 12374088) to M.L. Jin and J. Su.
Author information
Authors and Affiliations
Contributions
The authors’ contributions to this review are as follows: Initial conception and figures and tables: H.W., M.L.J. Guidance: S.S.G., J.S., M.L.J. Literature search and assembly: H.W., B.S. Writing: H.W, S.S.G., J.S., M.L.J. Editing: H.W, B.S., S.S.G., J.S., M.L.J.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, H., Sun, B., Ge, S.S. et al. On non-von Neumann flexible neuromorphic vision sensors. npj Flex Electron 8, 28 (2024). https://doi.org/10.1038/s41528-024-00313-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41528-024-00313-3
